Everything you need to know about Python 3.13 – JIT and GIL went up the hill
On 2nd October 2024, the Python core developers and community will release CPython v3.13.0 – and it’s a doozy. (Update: release has now been pushed back to 7th October.)
So what makes this release different, and why should you care about it?
In short, there are two big changes being made to how Python runs at a core level which have the potential to radically change the performance profile of Python code in the future.
Those changes are:
- A “free-threaded” version of CPython which allows you to disable the Global Interpreter Lock (GIL), and
- Support for experimental Just-in-Time (JIT) compilation.
So what are these new features and what impact will they have on you?
Global Interpreter Lock (GIL)
What is the GIL?
From the inception of the Python programming language by Guido Van Rossum in a science park in East Amsterdam in the late ’80s, it was designed and implemented as a single-threaded interpreted language. What exactly does this mean?
You’ll commonly hear that there are 2 types of programming languages – interpreted and compiled. So which is Python? The answer is: yes.
You will very rarely find a programming language which is purely interpreted from source by an interpreter. For interpreted languages, the human-readable source code is almost always compiled into some kind of intermediary form, called bytecode. The interpreter then looks at the bytecode and executes the instructions one-by-one.
The “interpreter” here is commonly called a “virtual machine”, especially in other languages like Java which does the same thing as Python re. Java bytecode and Java VMs. In Java and friends, it’s much more common to ship the compiled bytecode itself, whereas Python applications are usually distributed as source code (although, having said that, packages are often deployed as wheels as well as sdist nowadays).
Virtual machines in this meaning of the word come up in all kinds of unexpected places, like in the PostScript format (PDF files are essentially compiled PostScript) and in font rendering1.
If you’ve ever noticed a bunch of *.pyc files in your Python projects, this is the compiled bytecode for your application. You can decompile and explore pyc files in exactly the same way you can find Java class files.
Python vs CPython
I can already hear a chorus of pedantic Pythonistas shouting “Python isn’t the same as CPython!”, and they’re right. And this is an important distinction to make.
Python is the programming language, which is essentially a specification saying what the language should do.
CPython is the reference implementation of this language specification, and what we’re talking about here is mostly about the CPython implementation. There are other Python implementations, like PyPy which has always used JIT compilation, Jython which runs on the JVM and IronPython which runs on the .NET CLR.
Having said that, pretty much everyone just uses CPython and so I think it’s reasonable to talk about “Python” when we’re really talking about CPython. If you disagree, go ahead and get in the comments or write me a strongly worded email with an aggressive font (maybe Impact; I’ve always thought Comic Sans has a subtly threatening aura).
So when we run Python, the python executable will generate the bytecode which is a stream of instructions, then the interpreter will read and execute the instructions one-by-one.
If you try to spin up multiple threads, what happens then? Well, the threads all share the same memory (apart from their local variables) and so they can all access and update the same objects. Each thread will be executing its own bytecode using its own stack and instruction pointer.
What happens if multiple threads try to access / edit the same object at the same time? Imagine one thread is trying to add to a dict while another is trying to read from it. There are two options here:
- Make the implementation of dict (and all the other objects) thread-safe, which takes a lot of effort and will make it slower for a single-threaded application, or
- Create a global mutual exclusion lock (a.k.a. mutex) which allows only one thread to be executing bytecode at any one time.
This latter option is the GIL. The former option is what the Python developers are calling “free-threading” mode.
It’s also worth mentioning that the GIL makes garbage collection much simpler and faster. We don’t have time to go into the depths of garbage collection here as it’s a whole big topic in itself, but a simplified version is that Python keeps a count of how many references there are to a particular object, and when that count reaches zero, Python knows that it can safely delete that object. If there are multiple threads concurrently creating and dropping references to different objects, this can lead to race conditions and memory corruptions, so any free-threaded version needs to use atomically counted references for all objects.
The GIL also makes it much easier to develop C extensions for Python (e.g. using the confusingly named Cython) as you can make assumptions about thread safety that make your life much easier, check out the py-free-threading guide for porting C extensions for more details on this.
Why does Python have a GIL?
Despite having a surge in popularity over the last few years, it’s not a particularly new language – it was conceived in the late ’80s, with the first release on 20th February 1991 (making it slightly older than me). Back then, computers looked very different. Most programs were single-threaded and the performance of individual cores was increasing exponentially (see good old Moore’s Law). In this environment, it didn’t make much sense to compromise single-threaded performance for thread safety when most programs would not be utilising multiple cores.
Also, implementing thread safety obviously takes a lot of work.
This isn’t to say that you can’t utilise multiple cores in Python. It just means that instead of using threading, you have to utilise multiple processes (i.e. multiprocessing module).
Multi-processing differs from multi-threading because each process is its own Python interpreter with its own separate memory space. This means that multiple processes can’t access the same objects in memory but instead you have to use special constructs and communication to share data (see “Sharing state between processes” and multiprocessing.Queue).
It’s worth mentioning that there is a bit more overhead in using multiple processes as opposed to multiple threads, in addition to it being more difficult to share data.
Using multiple threads is sometimes not as bad as people commonly assume, however. If Python is doing I/O like reading from files or making network calls, it will release the GIL so that other threads can run. This means that if you’re doing lots of I/O, multi-threading will often be as fast as multi-processing. It’s when you are CPU-bound that the GIL becomes a big issue.
Ok, so why are they removing the GIL now?
The removal of the GIL has been something that certain people have been pushing for for several years now, but the main reason it’s not been done is not the amount of work it takes but instead is the corresponding performance degradation that would come with it for single-threaded programs.
Nowadays, the incremental improvements in single-core performance of computers doesn’t change too much from year to year (although big advances are being made with custom processor architectures, e.g. Apple Silicon chips) while the number of cores in a computer continues to increase. This means it’s much more common for programs to utilise multiple cores and hence the inability of Python to properly utilise multi-threading is becoming more and more of an issue.
Fast forward to 2021 and Sam Gross implemented a no-GIL Proof of Concept implementation that spurred the Python Steering Council to propose a vote on PEP 703 – Making the Global Interpreter Lock Optional in CPython. The outcome of the vote was positive, resulting in the Steering Council accepting the proposal as part of a gradual rollout in three phases:
- Phase 1: Free-threading mode is an experimental build-time option that is not the default.
- Phase 2: Free-threading mode is officially supported but still not the default.
- Phase 3: Free-threading mode is the default.
From reading the discussions, there’s a strong desire to not “split” Python into two separate implementations – one with the GIL and one without – with the intention being that eventually after free-threading mode has been the default for a while, the GIL will be removed entirely and the free-threading mode will be the only mode.
While all this GIL vs. no-GIL stuff has been going on the last few years, there has been a parallel effort called the “Faster CPython” project. This has been funded by Microsoft and led by Mark Shannon and Guido van Rossum himself, both of whom work at Microsoft.
The effort this team have been making has produced some very impressive results, particularly for 3.11 which boasted significant performance boosts over 3.10.
With the combination of community / council support, increasing ubiquity of multi-core processors and the Faster CPython effort, the time was ripe for the beginning of Phase 1 of the GIL adoption plan.
What does the performance look like?
I’ve run a few benchmarks on both my machine – MacBook Pro with Apple M3 Pro (CPU has 6 performance cores and 6 efficiency cores) – and on a quiet EC2 instance – t3.2xlarge (8 vCPUs).
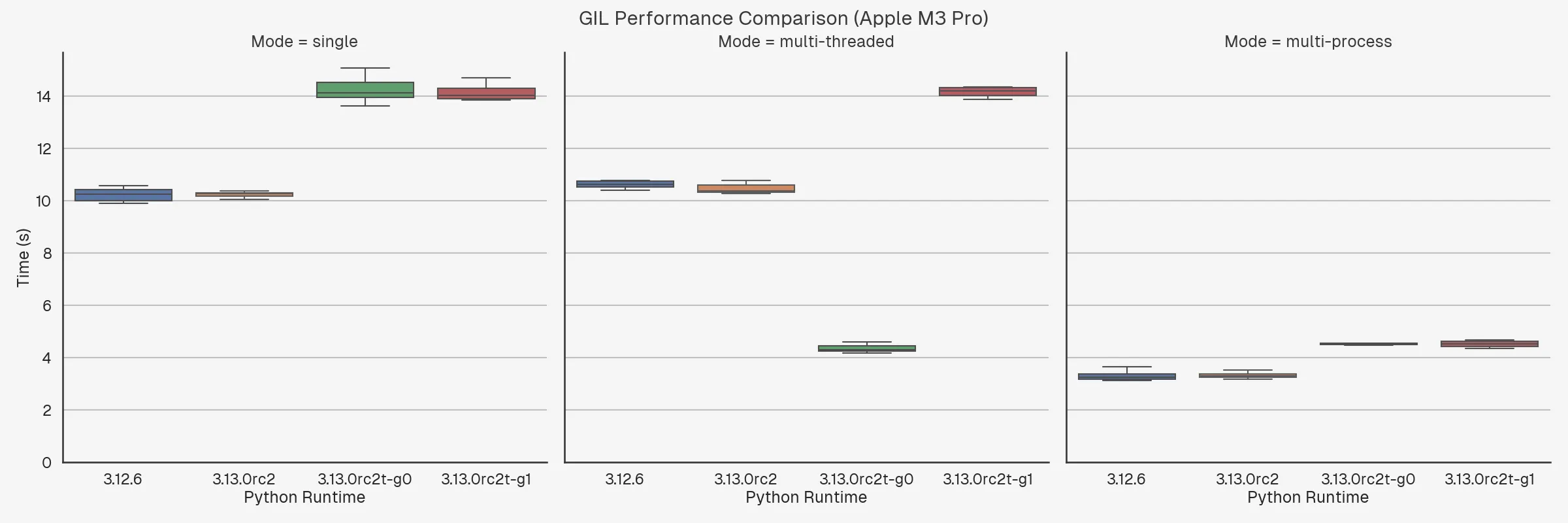
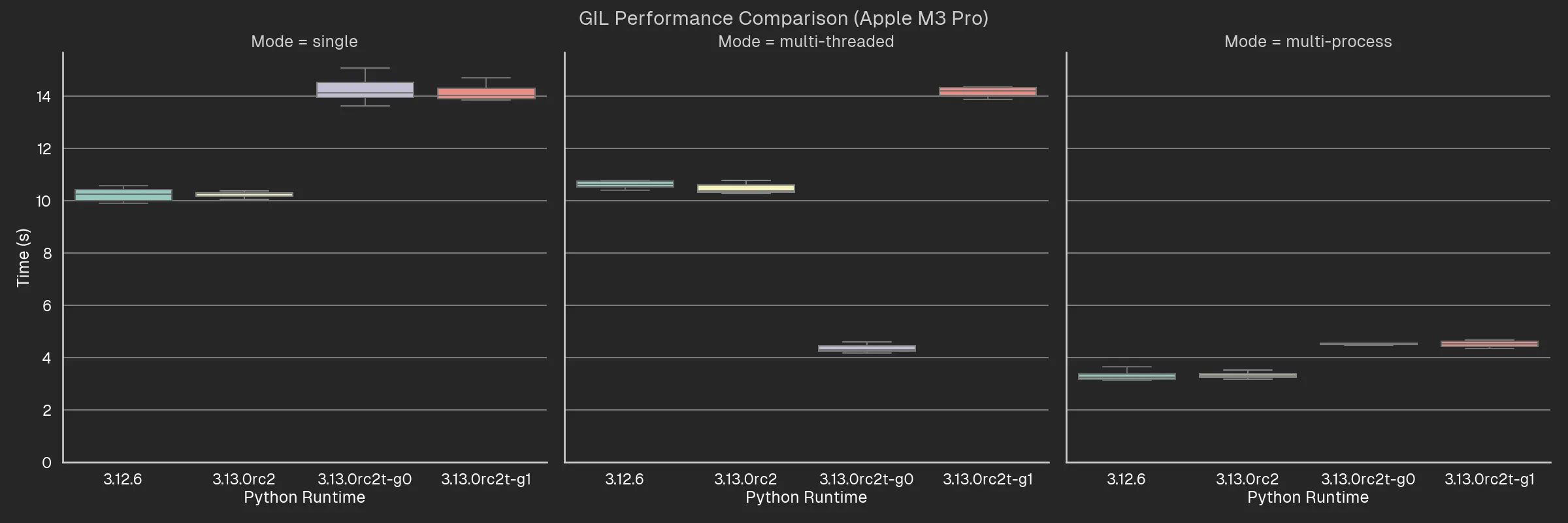
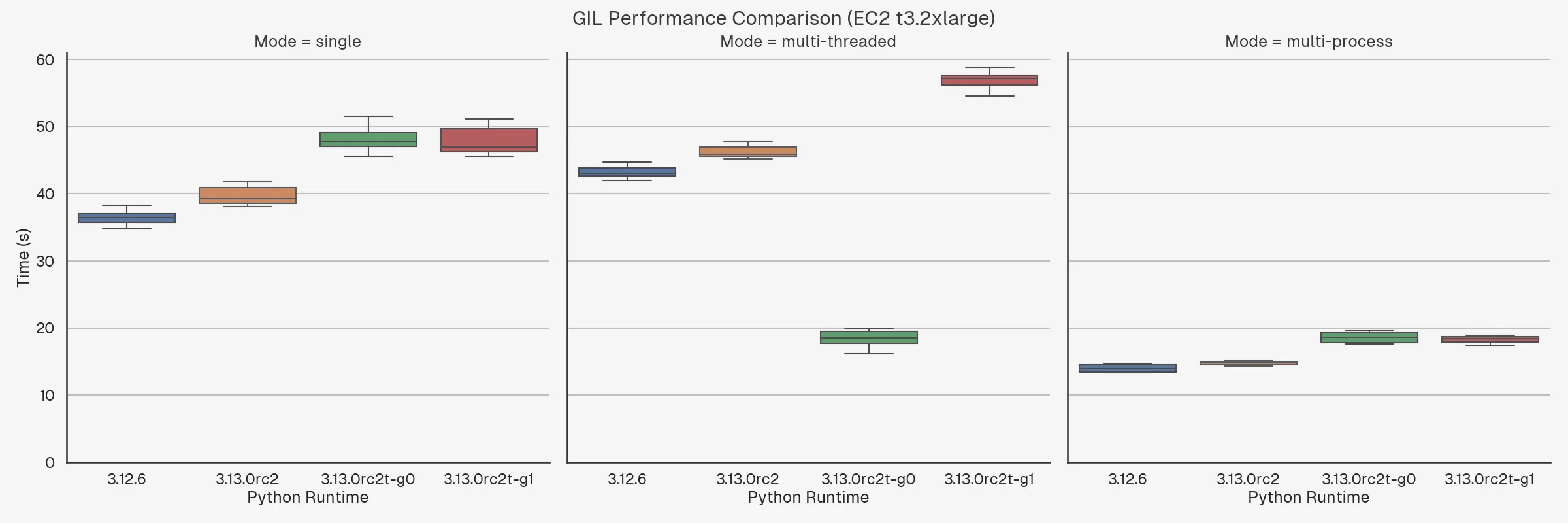
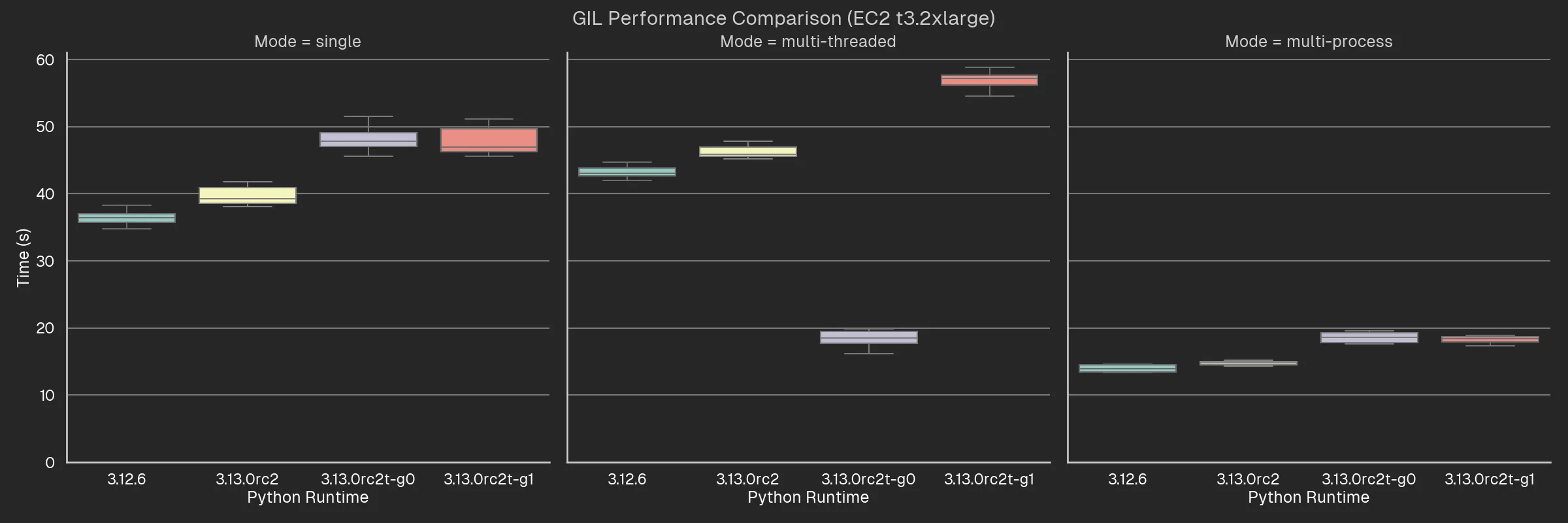
The graphs below show a comparison of the runtime performance of a CPU-intensive task (converging Mandelbrot set) between Python 3.12 and Python 3.13 with and without the GIL.
To explain what these runtimes mean:
3.12.6– Python version 3.12.6.3.13.0rc2– the default build of Python 3.13.0 release candidate 2 (the latest version at the time of writing).3.13.0rc2t-g0– the Python 3.13.0 release candidate 2 with experimental free-threading enabled at build-time, run with the-X gil=0argument, thereby ensuring the GIL is disabled even if imported libraries are not marked as supporting it.3.13.0rc2t-g1– the Python 3.13.0 release candidate 2 with experimental free-threading enabled at build-time, run with the-X gil=1argument, thereby “re-enabling” the GIL at runtime.
A few caveats to this:
- I didn’t use a proper well established benchmark, just a simple iterative algorithm. You can find the code for running the benchmarks and graphing the results at: github.com/drewsilcock/gil-perf. Try it out for yourself!
- I used hyperfine to run the benchmarks, which is a really good tool, but these aren’t proper scientific benchmarks running on dedicated hardware. My MacBook is running a whole bunch of things and even the EC2 instance will have stuff going on in the background, although not nearly as much.
- These benchmarks are really interesting and fun to talk about, but do bear in mind that in the real world, most libraries that do CPU-intensive work use Cython or similar – very few people use raw Python for very compute-intensive tasks. Cython has the ability to release the GIL temporarily during execution and has had for a while. These benchmarks aren’t representative of this use case.
With that in mind, we can already make a few observations:
- The performance degradation when Python is built with free-threading support is significant – around 20%.
- It doesn’t matter whether you re-enable the GIL via the
-X gil=1argument, the performance degradation is the same. - Multi-threading shows a significant boost with GIL disabled, as expected.
- Multi-threading with GIL enabled is slower than single-threading, as expected.
- Multi-threading with GIL disabled is about the same as multi-processing. Then again, this is a pretty noddy example where you don’t need to do much real work.
- Apple Silicon chips really are quite impressive. Single-threaded performance on my M3 Pro is about 4x faster than single-threaded performance on the t3.2xlarge. I mean, I know t3 are designed to be cheap and burstable, but even so! It’s even more impressive if you consider the insane battery life you get out of these things2.
Update 2024-09-30: how do they scale?
I’ve run a few extra benchmarks to see how the performance scales with the number of threads / processes. Here are the graphs in seconds:
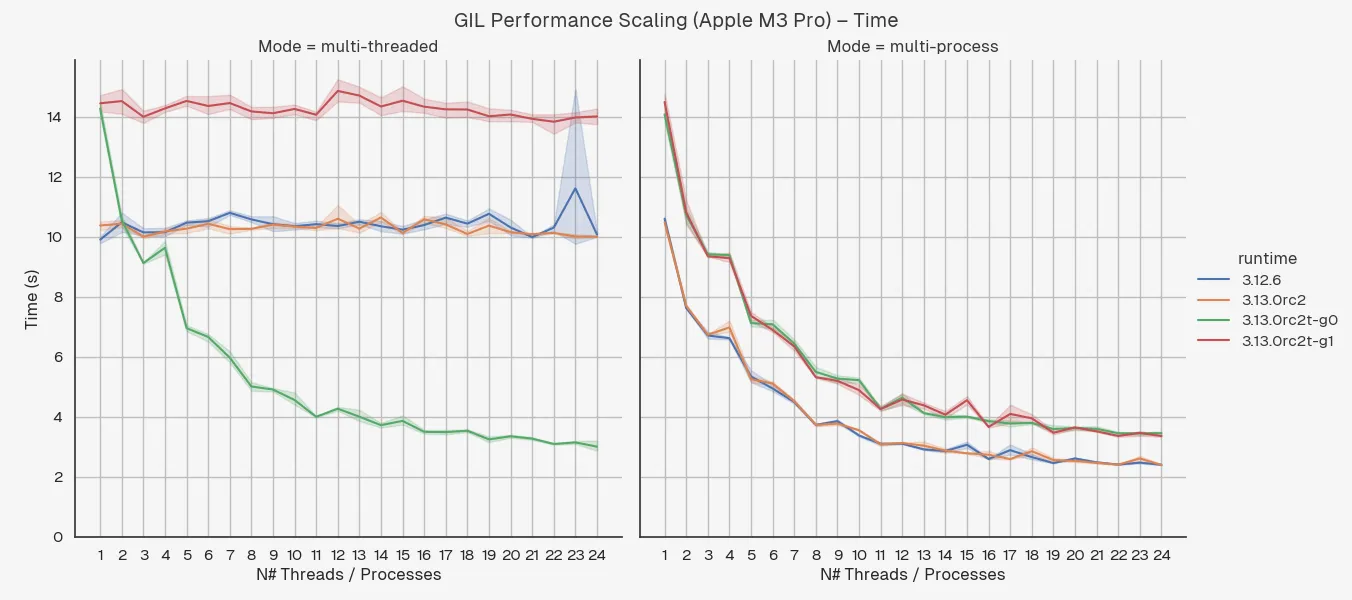
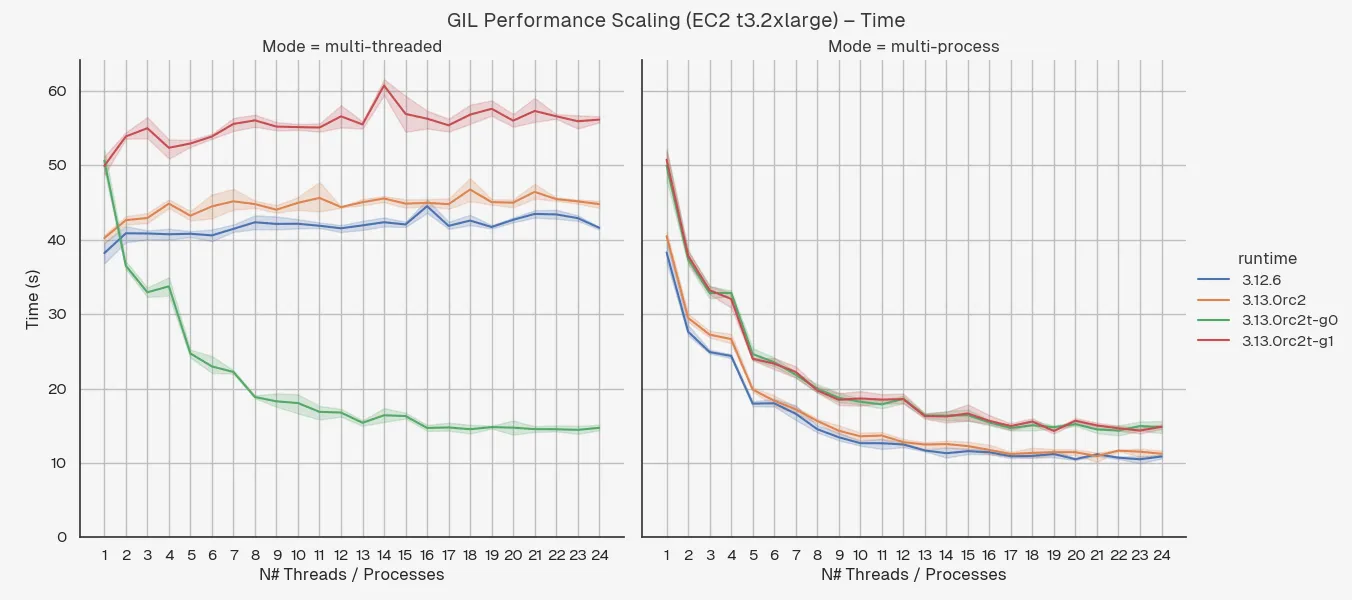
(Don’t ask what was happening on chunk 23 on my MacBook, something obviously decided to take up a lot of CPU in the background.)
As expected, changing the number of threads doesn’t change the performance of the GIL-enabled runtimes while both the GIL-disabled runtimes and multi-processing modes give a nice curve tending to a minimum execution time, where the non-parallel portion and hardware limitations (i.e. number of physical cores) restrict the performance improvements.
I was a bit surprised that the performance continued to improve way past the number of physical cores for both multi-threaded and multi-processing modes. The M3 has 12 cores and doesn’t do any Simultaneous Multi-Threading (SMT)3 while the t3.2xlarge has 8 vCPUs which is actually just 4 cores with SMT so I don’t quite get how you’re still seeing better performance at 16 threads / processes than 15. Leave a comment or email if you’ve got an idea for why this is!
This becomes even more clear when you plot is as a speedup fraction:
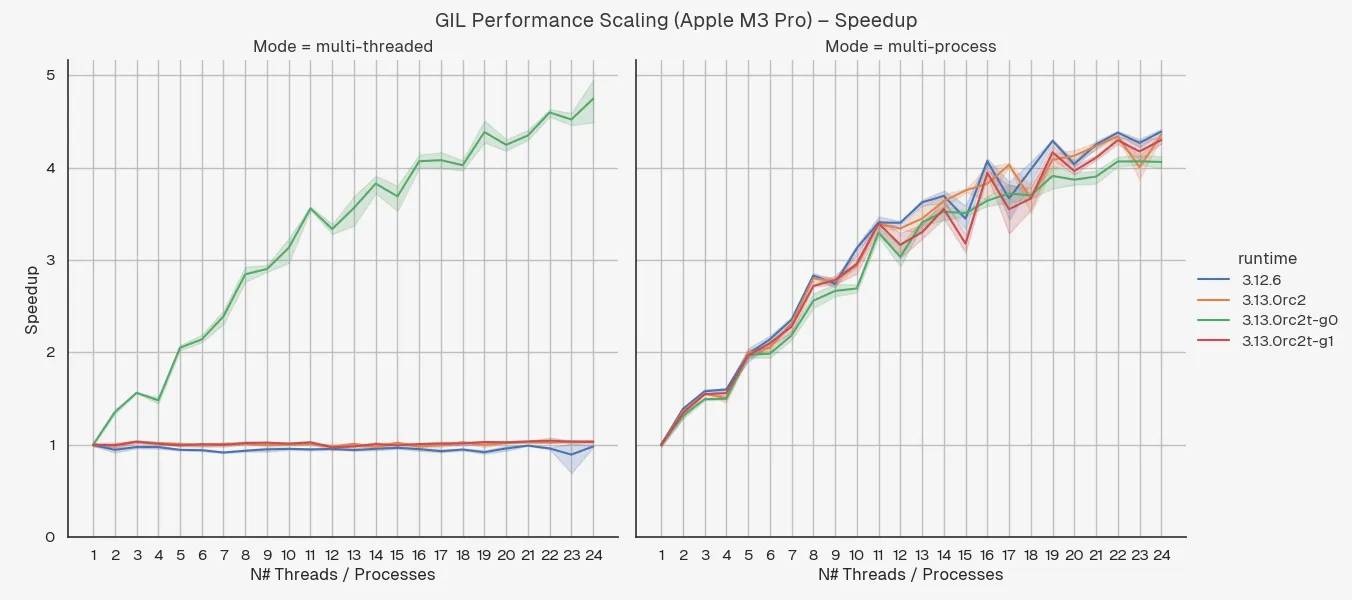
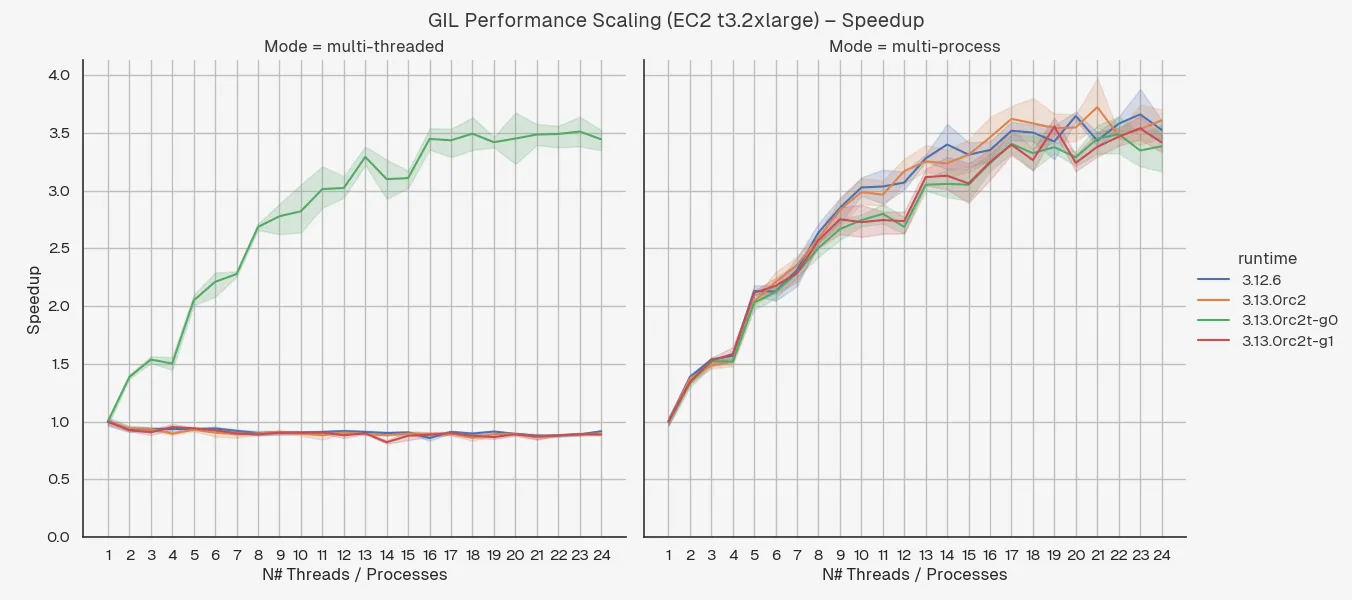
This shows the same data as before but where each data point is scaled as the performance improvement over base case (where the number of threads / processes is 1) for that runtime and mode.
People who care about performance like to plot it like this so that they can compare it to Amdahl’s Law which is a theoretical limit on how much you can speed up a program by parallelising it, although this obviously isn’t a proper performance analysis, it’s mostly just for fun 😎📈
How do I try out free-threaded Python?
At the time of writing, Python 3.13 is still in release candidate and hasn’t been officially released. Having said that, today is Saturday 28th September and the release is scheduled for 2nd 7th October which is Wednesday a week on Thursday, so its not far away. (Update: updated release date to reflect pushed back release schedule.)
If you want to try it out ahead of time, you’re out of luck with rye which only seems to ship deployed versions and uv which includes the 3.13.0rc2 build but not the 3.13.0rc2t build. Luckily, pyenv supports both 3.13.0rc2 and 3.13.0rc2t. To try it out for yourself:
1# If you're reading this from the future, rye may have it:23
4# uv may also have it5$ uv python list | rg -F cpython-3.136
7# pyenv should have it, though.8$ pyenv install --list | rg '^\s+3\.13'9
10# Take 3.13.0rc2t for a spin11$ pyenv install 3.13.0rc2t12$ pyenv local 3.13.0rc2t13
14$ python -VV15Python 3.13.0rc2 experimental free-threading build (main, Sep 18 2024, 16:41:38) [Clang 15.0.0 (clang-1500.3.9.4)]16
17$ python -c 'import sys;print("GIL enabled 🔒" if sys._is_gil_enabled() else "GIL disabled 😎")'18GIL disabled 😎19
20# GIL can be re-enabled at runtime21$ python -X gil=1 -c 'import sys;print("GIL enabled 🔒" if sys._is_gil_enabled() else "GIL disabled 😎")'22GIL enabled 🔒Just a heads up if you are trying free-threading Python – if you don’t specify either -X gil=0 or -X gil=1, the GIL will be disabled by default but simply importing a module which does not support running without the GIL will cause the GIL to be re-enabled. I found this when running the benchmarks because I imported matplotlib, which results in the GIL being re-enabled and all my benchmarks coming out rubbish. If you manually specify -X gil=0, the GIL will not be sneakily re-enabled, even if a package does not mark itself as supporting GIL-free running.
JIT (Just-in-Time) Compiler
It’s not just the GIL that’s a big change in this Python release – there’s also the addition into the Python interpreter of an experimental JIT compiler.
What is a JIT?
JIT stands for Just in Time and is a compilation technique where machine code is produced just in time to execute it, as opposed to ahead of time (AOT) like your traditional C compiler like gcc or clang.
We already talked about bytecode and the interpreter earlier. The important thing is that, before Python 3.13, the interpreter would look at each bytecode instruction one at a time and turn each one into native machine code before executing it. With the introduction of the JIT compiler, it is now possible for bytecode to be “interpreted” into machine code once and updated as necessary, instead of being re-interpreted every time.
It’s important to point out that this kind of JIT that has been introduced in 3.13 is what’s called “copy-and-patch” JIT. This is a very recent idea introduced in 2021 in an article called “Copy-and-patch compilation: a fast compilation algorithm for high-level languages and bytecode. The core idea behind copy-and-patch as opposed to more advanced JIT compilers is that there is a simple list of pre-generated templates – the JIT compiler will pattern match for bytecode that matches one of the pre-defined templates and if it does, it will patch in pre-generated native machine code.
Traditional JIT compilers will be massively more advanced that this and also massively more memory intensive, especially if you compare it to heavily JIT-compiled languages like Java or C#. (That’s part of the reason Java programs take up so much memory.)
What’s great about JIT compilers is that they can adapt to your code as its running. For instance, as your code runs, the JIT compiler will keep track of how “hot” each piece of code is. JIT compilers can perform incremental optimisations as the code get hotter and hotter and even use information about how the program is actually running to inform the optimisations it is making (like how Profile-Guided Optimisation does for AOT compilers). This means that JIT doesn’t waste time optimising some code which is only running once but the really hot sections of code can have heavy run-time informed optimisations done on them.
Now, the JIT compiler in Python 3.13 is relatively simple and won’t be doing any crazy at this stage, but it’s a really exciting development for the future of Python performance.
What difference will the JIT make to me?
In the short term, the introduction of the JIT is unlikely to make any difference to how you write or run your Python code. But it’s an exciting internal change to the way that the Python interpreter operates that could lead to much more significant performance improvements being made to Python performance in the future.
In particular, it opens up the way for incremental performance improvements to be made over time which could gradually bump up Python’s performance to be more competitive with other languages. Having said that, this is still early stages and the copy-and-patch JIT technique is both new and lightweight, so there’s more big changes needed before we start seeing significant benefits from the JIT compiler.
How do I try out the JIT?
The JIT compilers is “experimental” in 3.13 and isn’t built with support out of the box (at least not when I downloaded 3.13.0rc2 using pyenv). You can enable experimental JIT support by doing:
1$ PYTHON_CONFIGURE_OPTS="--enable-experimental-jit" pyenv install 3.13-dev2python-build: use openssl@3 from homebrew3python-build: use readline from homebrew4Cloning https://github.com/python/cpython...5Installing Python-3.13-dev...6python-build: use tcl-tk from homebrew7python-build: use readline from homebrew8python-build: use ncurses from homebrew9python-build: use zlib from xcode sdk10Installed Python-3.13-dev to /Users/drew.silcock/.pyenv/versions/3.13-dev11$ python -c 'import sysconfig;print("JIT enabled 🚀" if "-D_Py_JIT" in sysconfig.get_config_var("PY_CORE_CFLAGS") else "JIT disabled 😒")'12JIT enabled 🚀There are additional configure options which you can read about on the PEP 744 discussion page (like enabling the JIT but requiring it be enabled by running -X jit=1 at runtime, etc.).
The test here only checks for whether the JIT was enabled at built-time, not whether it’s currently running (e.g. has been disabled at runtime). It is possible to check at runtime whether the JIT is enabled, but it’s a bit more tricky. Here’s a script you can use to figure it out (taken from the PEP 744 discussion page)4:
1import _opcode2import types3
4
5def is_jitted(f: types.FunctionType) -> bool:6 for i in range(0, len(f.__code__.co_code), 2):7 try:8 _opcode.get_executor(f.__code__, i)9 except RuntimeError:10 # This isn't a JIT build:11 return False12 except ValueError:13 # No executor found:14 continue15 return True16 return False17
18
19def fibonacci(n):20 a, b = 0, 121 for _ in range(n):22 a, b = b, a + b23 return a24
25
26def main():27 fibonacci(100)28 if is_jitted(fibonacci):29 print("JIT enabled 🚀")30 else:31 print("Doesn't look like the JIT is enabled 🥱")32
33
34
35if __name__ == "__main__":36 main()The PEP 744 discussion has mention of both PYTHON_JIT=0/1 and -X jit=0/1 – I did not find that the -X option did anything at all, but the environment variable seems to do the trick.
1$ python is-jit.py2JIT enabled 🚀3$ PYTHON_JIT=0 python is-jit.py4Doesn't look like the JIT is enabled 🥱Conclusion
Python 3.13 is a big release in introducing some exciting new concepts and features to the runtime. It’s unlikely to make any immediate different to how you write and run your Python, but it’s likely that over the next few months and years as both free-threading and JIT become more mature and well established, they’ll begin to have more and more of an impact on the performance profile of Python code, particularly for CPU-bound tasks.
Further reading
- PEP 703 – Making the Global Interpreter Lock Optional in CPython
- py-free-threading
- Python 3.13 gets a JIT – Anthony Shaw
- PEP 744 – JIT Compilation
- Discuss – PEP 744: JIT Compilation
Updates
- 2024-09-28: Updated release date for v3.13.0 from 2nd October to 7th October. Thanks to nmstoker on HN for pointing this out.
- 2024-09-30: Updated graphs to be more readable and added extra section on performance scaling.
Footnotes
-
Font rendering is a fascinating topic and that immensely complex. Trust me, however complicated you think font rendering is, it’s more complicated that that. IIRC most of the complexity actually comes from nicely drawing text at small resolutions. For instance, in TrueType both a whole font and individual glyphs have instructions associated with them which are executed by the FontEngine virtual machine a.k.a. interpreter. If this is something you’re interested in learning more about, I highly recommend Sebastian Lague’s video – Coding Adventure: Rendering Text. He makes really great videos. The TrueType reference is also surprisingly readable. ↩
-
Apple aren’t even paying me to say this stuff, it’s just true. ↩
-
Some people use “hyper-threading” as a generic term for SMT, but hyper-threading is the Intel-specific brand name for their implementation of SMT, while SMT is the generic term for the technology, so we should call it SMT. ↩
-
I also found a few people online talking about how you could use
sysconfig.get_config_var("JIT_DEPS")but I did not found that this worked at all for me. ↩
Comments