How Postgres stores oversized values – let's raise a TOAST
This post is part 2 of a series on Postgres internals – for part 1, see How Postgres stores data on disk – this one’s a page turner.
Where we left off last time, we had a table stored as heap segments, with each segment containing a bunch of pages, each of size 8 KiB. This was working fantastically for our table of countries, but you might be wondering – if each page is 8 KiB in size and a single row can’t span multiple pages, what happens if we’ve got a single value which is bigger than 8 KiB?
Let’s find out.
Recap
(If you’ve just come from part 1 and still have the database setup, feel free to skip over this bit.)
Last time we spin up a fresh Postgres instance and inserted a load of countries in from CSV. You can re-create this by running:
1mkdir pg-data2
3curl 'https://raw.githubusercontent.com/lukes/ISO-3166-Countries-with-Regional-Codes/master/all/all.csv' \4 --output ./pg-data/countries.csv5
6docker run -d --rm -v ./pg-data:/var/lib/postgresql/data -e POSTGRES_PASSWORD=password postgres:167
8pg_container_id=$(docker ps --filter expose=5432 --format "{{.ID}}")9
10docker exec $pg_container_id psql -U postgres -c 'create database blogdb; create extension pageinspect;'Now the database is set up, you can start a psql session with:
1docker exec -it $pg_container_id psql -U postgres blogdbNext create the schema and load the data in with:
1create table countries (2 id integer primary key generated always as identity,3 name text not null unique,4 alpha_2 char(2) not null,5 alpha_3 char(3) not null,6 numeric_3 char(3) not null,7 iso_3166_2 text not null,8 region text,9 sub_region text,10 intermediate_region text,11 region_code char(3),12 sub_region_code char(3),13 intermediate_region_code char(3)14);15
16copy countries (17 name,18 alpha_2,19 alpha_3,20 numeric_3,21 iso_3166_2,22 region,23 sub_region,24 intermediate_region,25 region_code,26 sub_region_code,27 intermediate_region_code28)29from '/var/lib/postgresql/data/countries.csv'30with csv header;From this we explained how Postgres stores tables in separate 1 GiB files called segments, with each segment consisting of a series of pages of 8 KiB each. Each page has a number of tuples within it which represents a snapshot view of a row at a particular time. Updating or deleting a row does not remove the tuple but instead creates a new tuple at the end of the last page. The old or “dead” tuple is only cleared out once Postgres runs a vacuum.
The filename of the first segment is stored in base/{database oid}/{filenode} where OID = Object IDentifier and filenode is an integer that starts off equal to table OID but diverges over time as the database runs vacuums and other operations. You can find your database’s OID and table’s filenode by running:
1-- Database object ID2select oid from pg_database where datname = 'blogdb';3
4-- Table filenode5select relfilenode from pg_class where relname = 'countries';Within each row there is a secret column not returned from select * called ctid that refers to the tuple’s physical location on disk. It looks like (page index, tuple index within page), e.g. (3, 7) refers to tuple #7 within page #3. You can return this secret column by simply doing select ctid, * instead of select *.
You can use the built-in pageinspect extension to examine page headers and their raw data using page_header() and heap_page_items() functions alongside get_raw_page().
Let’s create another table
Last time we made a table of countries from the ISO 3611-1 spec. Let’s say now that we want to add some of the greatest creative works that these countries have to offer (that also happen to have their copyright expired).
To prepare for this, we’ll create a new table for these culturally important creative works.
If you didn’t go through the recap steps above, make sure your database is running:
1docker run -d --rm -v ./pg-data:/var/lib/postgresql/data -e POSTGRES_PASSWORD=password postgres:162pg_container_id=$(docker ps --filter expose=5432 --format "{{.ID}}")Reminder: To open an interactive psql session, run:
1docker exec -it $pg_container_id psql -U postgres blogdbHere’s our table schema:
1create table creative_works (2 id integer primary key generated always as identity,3 title text,4 authors jsonb,5 -- In real life this would probably be a many-to-many relationship instead of6 -- one-to-many, just take a look at:7 -- https://en.wikipedia.org/wiki/Wikipedia:Lamest_edit_wars/Ethnic_feuds#People8 country_id integer references countries (id),9 content text10);I’ve prepared three poems of varying length and formatted it as CSV so that you can quickly load it into your database:
1curl 'https://drew.silcock.dev/data/poems.csv' --output ./pg-data/poems.csvNext let’s copy the CSV into our new table – we’ll use a temporary table to resolve the country code to country ID.
1begin;2
3create temporary table creative_works_temp (4 title text,5 authors jsonb,6 country_code char(2),7 content text8) on commit drop;9
10copy creative_works_temp (title, authors, country_code, content)11from '/var/lib/postgresql/data/poems.csv'12with csv header;13
14insert into creative_works15select cw.title, cw.authors, c.id, cw.content16from creative_works_temp cw17left join countries c on c.alpha_2 = cw.country_code;18
19end;Just like before, we’re going to use the pageinspect functions to explore what the raw data looks like1:
1blogdb=# select id, title, authors, country_id, length(content) from creative_works;2 id | title | authors | country_id | length3----+----------------------+-------------------------------------------------------------------------------------+------------+--------4 12 | Ozymandias | [{"name": "Percy Bysshe Shelley", "birth_year": 1792, "death_year": 1822}] | 235 | 6315 13 | Ode on a Grecian Urn | [{"name": "Keats, John", "birth_year": 1795, "death_year": 1821}] | 235 | 24426 14 | The Waste Land | [{"name": "Eliot, T. S. (Thomas Stearns)", "birth_year": 1888, "death_year": 1965}] | 236 | 199507(3 rows)8
9blogdb=# select lp, lp_off, lp_flags, lp_len, t_xmin, t_xmax, t_field3, t_ctid, t_infomask2, t_infomask, t_hoff, t_bits, t_oid, length(t_data)10blogdb-# from heap_page_items(get_raw_page('creative_works', 0));11 lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | length12----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+--------13 1 | 7408 | 1 | 781 | 1074 | 0 | 8 | (0,1) | 5 | 2818 | 24 | | | 75714 2 | 5536 | 1 | 1868 | 1074 | 0 | 8 | (0,2) | 5 | 2818 | 24 | | | 184415 3 | 5360 | 1 | 174 | 1074 | 0 | 8 | (0,3) | 5 | 2822 | 24 | | | 15016(3 rows)We can see that we have added three classic poems to our table of increasing length:
- Ozymandias by Percy Bysshe Shelley – a short but intense exploration of the futility of hubris and how time washes away even the greatest of empires. Clocking in at 631 characters, this is the shortest poem of the lot. The size of the whole row is 757 bytes which makes sense – 631 for the actual poem and 126 for the title, authors and country ID2.
- Ode on a Grecian Urn by John Keats – a slightly longer 2,442 character ode praising an ancient Greek urn and the scenes depicted on it. This poem is 2,442 characters long, and yet the whole row is only 1,844 bytes 🤔
- The Waste Land by T. S. Eliot – the 434 lines of this 1922 poem are split between 5 sections and flows between different styles, times, places, narrators and themes. This is by far the longest at 19,950 characters yet the tuple in the heap table is only 150 bytes!
Show me the data
We can figure out what’s going on by looking at the raw data for each row. Let’s write a little helper Bash function for this:
1function run-and-decode {2 # You can replace `hexyl` for `xxd` if you don't have hexyl installed.3 docker exec $pg_container_id psql -U postgres blogdb --tuples-only -c "$1" | cut -c4- | xxd -r -p | hexyl4}5
6function print-cw-data {7 query="with cw as (8 select ctid9 from creative_works where title = '$1'10 )11 select t_data12 from heap_page_items(13 get_raw_page(14 'creative_works',15 (select (ctid::text::point)[0]::bigint from cw)16 )17 )18 where t_ctid = (select ctid from cw)19 order by lp desc limit 1"20 run-and-decode "$query"21}Let’s start with Ozymandias:
1$ print-cw-data 'Ozymandias'2┌────────┬─────────────────────────┬─────────────────────────┬────────┬────────┐3│00000000│ 01 00 00 00 17 4f 7a 79 ┊ 6d 61 6e 64 69 61 73 c3 │•⋄⋄⋄•Ozy┊mandias×│4│00000010│ 01 00 00 40 58 00 00 d0 ┊ 03 00 00 20 04 00 00 80 │•⋄⋄@X⋄⋄×┊•⋄⋄ •⋄⋄×│5│00000020│ 0a 00 00 00 0a 00 00 00 ┊ 14 00 00 00 08 00 00 10 │_⋄⋄⋄_⋄⋄⋄┊•⋄⋄⋄•⋄⋄•│6│00000030│ 08 00 00 10 6e 61 6d 65 ┊ 62 69 72 74 68 5f 79 65 │•⋄⋄•name┊birth_ye│7│00000040│ 61 72 64 65 61 74 68 5f ┊ 79 65 61 72 50 65 72 63 │ardeath_┊yearPerc│8│00000050│ 79 20 42 79 73 73 68 65 ┊ 20 53 68 65 6c 6c 65 79 │y Bysshe┊ Shelley│9│00000060│ 20 00 00 00 00 80 00 07 ┊ 20 00 00 00 00 80 1e 07 │ ⋄⋄⋄⋄×⋄•┊ ⋄⋄⋄⋄ו•│10│00000070│ eb 00 00 00 04 0a 00 00 ┊ 49 20 6d 65 74 20 61 20 │×⋄⋄⋄•_⋄⋄┊I met a │11│00000080│ 74 72 61 76 65 6c 6c 65 ┊ 72 20 66 72 6f 6d 20 61 │travelle┊r from a│12│00000090│ 6e 20 61 6e 74 69 71 75 ┊ 65 20 6c 61 6e 64 2c 0a │n antiqu┊e land,_│13│000000a0│ 57 68 6f 20 73 61 69 64 ┊ e2 80 94 e2 80 9c 54 77 │Who said┊××××××Tw│14│000000b0│ 6f 20 76 61 73 74 20 61 ┊ 6e 64 20 74 72 75 6e 6b │o vast a┊nd trunk│15│000000c0│ 6c 65 73 73 20 6c 65 67 ┊ 73 20 6f 66 20 73 74 6f │less leg┊s of sto│16│000000d0│ 6e 65 0a 53 74 61 6e 64 ┊ 20 69 6e 20 74 68 65 20 │ne_Stand┊ in the │17│000000e0│ 64 65 73 65 72 74 2e 20 ┊ 2e 20 2e 20 2e 20 4e 65 │desert. ┊. . . Ne│18│000000f0│ 61 72 20 74 68 65 6d 2c ┊ 20 6f 6e 20 74 68 65 20 │ar them,┊ on the │19│00000100│ 73 61 6e 64 2c 0a 48 61 ┊ 6c 66 20 73 75 6e 6b 20 │sand,_Ha┊lf sunk │20│00000110│ 61 20 73 68 61 74 74 65 ┊ 72 65 64 20 76 69 73 61 │a shatte┊red visa│21│00000120│ 67 65 20 6c 69 65 73 2c ┊ 20 77 68 6f 73 65 20 66 │ge lies,┊ whose f│22│00000130│ 72 6f 77 6e 2c 0a 41 6e ┊ 64 20 77 72 69 6e 6b 6c │rown,_An┊d wrinkl│23│00000140│ 65 64 20 6c 69 70 2c 20 ┊ 61 6e 64 20 73 6e 65 65 │ed lip, ┊and snee│24│00000150│ 72 20 6f 66 20 63 6f 6c ┊ 64 20 63 6f 6d 6d 61 6e │r of col┊d comman│25│00000160│ 64 2c 0a 54 65 6c 6c 20 ┊ 74 68 61 74 20 69 74 73 │d,_Tell ┊that its│26│00000170│ 20 73 63 75 6c 70 74 6f ┊ 72 20 77 65 6c 6c 20 74 │ sculpto┊r well t│27│00000180│ 68 6f 73 65 20 70 61 73 ┊ 73 69 6f 6e 73 20 72 65 │hose pas┊sions re│28│00000190│ 61 64 0a 57 68 69 63 68 ┊ 20 79 65 74 20 73 75 72 │ad_Which┊ yet sur│29│000001a0│ 76 69 76 65 2c 20 73 74 ┊ 61 6d 70 65 64 20 6f 6e │vive, st┊amped on│30│000001b0│ 20 74 68 65 73 65 20 6c ┊ 69 66 65 6c 65 73 73 20 │ these l┊ifeless │31│000001c0│ 74 68 69 6e 67 73 2c 0a ┊ 54 68 65 20 68 61 6e 64 │things,_┊The hand│32│000001d0│ 20 74 68 61 74 20 6d 6f ┊ 63 6b 65 64 20 74 68 65 │ that mo┊cked the│33│000001e0│ 6d 2c 20 61 6e 64 20 74 ┊ 68 65 20 68 65 61 72 74 │m, and t┊he heart│34│000001f0│ 20 74 68 61 74 20 66 65 ┊ 64 3b 0a 41 6e 64 20 6f │ that fe┊d;_And o│35│00000200│ 6e 20 74 68 65 20 70 65 ┊ 64 65 73 74 61 6c 2c 20 │n the pe┊destal, │36│00000210│ 74 68 65 73 65 20 77 6f ┊ 72 64 73 20 61 70 70 65 │these wo┊rds appe│37│00000220│ 61 72 3a 0a 4d 79 20 6e ┊ 61 6d 65 20 69 73 20 4f │ar:_My n┊ame is O│38│00000230│ 7a 79 6d 61 6e 64 69 61 ┊ 73 2c 20 4b 69 6e 67 20 │zymandia┊s, King │39│00000240│ 6f 66 20 4b 69 6e 67 73 ┊ 3b 0a 4c 6f 6f 6b 20 6f │of Kings┊;_Look o│40│00000250│ 6e 20 6d 79 20 57 6f 72 ┊ 6b 73 2c 20 79 65 20 4d │n my Wor┊ks, ye M│41│00000260│ 69 67 68 74 79 2c 20 61 ┊ 6e 64 20 64 65 73 70 61 │ighty, a┊nd despa│42│00000270│ 69 72 21 0a 4e 6f 74 68 ┊ 69 6e 67 20 62 65 73 69 │ir!_Noth┊ing besi│43│00000280│ 64 65 20 72 65 6d 61 69 ┊ 6e 73 2e 20 52 6f 75 6e │de remai┊ns. Roun│44│00000290│ 64 20 74 68 65 20 64 65 ┊ 63 61 79 0a 4f 66 20 74 │d the de┊cay_Of t│45│000002a0│ 68 61 74 20 63 6f 6c 6f ┊ 73 73 61 6c 20 57 72 65 │hat colo┊ssal Wre│46│000002b0│ 63 6b 2c 20 62 6f 75 6e ┊ 64 6c 65 73 73 20 61 6e │ck, boun┊dless an│47│000002c0│ 64 20 62 61 72 65 0a 54 ┊ 68 65 20 6c 6f 6e 65 20 │d bare_T┊he lone │48│000002d0│ 61 6e 64 20 6c 65 76 65 ┊ 6c 20 73 61 6e 64 73 20 │and leve┊l sands │49│000002e0│ 73 74 72 65 74 63 68 20 ┊ 66 61 72 20 61 77 61 79 │stretch ┊far away│50│000002f0│ 2e e2 80 9d 0a ┊ │.×××_ ┊ │51└────────┴─────────────────────────┴─────────────────────────┴────────┴────────┘We can see here the first 4 bytes are the ID, then the title, then a bunch of bytes for the jsonb blob containing the authors (Postgres does not store jsonb values as plain strings but that’s a story for another post), then we can see eb 00 00 00 – this is the country ID (in my database, the UK has ID 235 = 0xeb) – then we have the 4 bytes 04 0a 00 00 and finally the poem itself, in full. We mentioned those pesky 4 bytes in the last blog post that holds the varlena metadata – we’re going to talk about them again a little bit later on in this post.
Let’s take a look at Keats:
1$ print-cw-data 'Ode on a Grecian Urn' | head -n 302┌────────┬─────────────────────────┬─────────────────────────┬────────┬────────┐3│00000000│ 02 00 00 00 2b 4f 64 65 ┊ 20 6f 6e 20 61 20 47 72 │•⋄⋄⋄+Ode┊ on a Gr│4│00000010│ 65 63 69 61 6e 20 55 72 ┊ 6e b3 01 00 00 40 50 00 │ecian Ur┊nו⋄⋄@P⋄│5│00000020│ 00 d0 03 00 00 20 04 00 ┊ 00 80 0a 00 00 00 0a 00 │⋄ו⋄⋄ •⋄┊⋄×_⋄⋄⋄_⋄│6│00000030│ 00 00 0b 00 00 00 09 00 ┊ 00 10 08 00 00 10 6e 61 │⋄⋄•⋄⋄⋄_⋄┊⋄••⋄⋄•na│7│00000040│ 6d 65 62 69 72 74 68 5f ┊ 79 65 61 72 64 65 61 74 │mebirth_┊yeardeat│8│00000050│ 68 5f 79 65 61 72 4b 65 ┊ 61 74 73 2c 20 4a 6f 68 │h_yearKe┊ats, Joh│9│00000060│ 6e 00 20 00 00 00 00 80 ┊ 03 07 20 00 00 00 00 80 │n⋄ ⋄⋄⋄⋄×┊•• ⋄⋄⋄⋄×│10│00000070│ 1d 07 00 00 eb 00 00 00 ┊ f2 1a 00 00 8c 09 00 00 │••⋄⋄×⋄⋄⋄┊ו⋄⋄×_⋄⋄│11│00000080│ 00 54 68 6f 75 20 73 74 ┊ 69 00 6c 6c 20 75 6e 72 │⋄Thou st┊i⋄ll unr│12│00000090│ 61 76 00 69 73 68 27 64 ┊ 20 62 72 00 69 64 65 20 │av⋄ish'd┊ br⋄ide │13│000000a0│ 6f 66 20 71 00 75 69 65 ┊ 74 6e 65 73 73 18 2c 0a │of q⋄uie┊tness•,_│14│000000b0│ 20 03 01 02 31 66 6f 73 ┊ 00 74 65 72 2d 63 68 69 │ •••1fos┊⋄ter-chi│15│000000c0│ 6c 02 64 01 27 73 69 6c ┊ 65 6e 63 00 65 20 61 6e │l•d•'sil┊enc⋄e an│16│000000d0│ 64 20 73 6c 00 6f 77 20 ┊ 74 69 6d 65 2c 00 0a 53 │d sl⋄ow ┊time,⋄_S│17│000000e0│ 79 6c 76 61 6e 20 00 68 ┊ 69 73 74 6f 72 69 61 00 │ylvan ⋄h┊istoria⋄│18│000000f0│ 6e 2c 20 77 68 6f 20 63 ┊ 00 61 6e 73 74 20 74 68 │n, who c┊⋄anst th│19│00000100│ 75 00 73 20 65 78 70 72 ┊ 65 73 02 73 05 5c 41 20 │u⋄s expr┊es•s•\A │20│00000110│ 66 6c 6f 77 00 65 72 79 ┊ 20 74 61 6c 65 00 20 6d │flow⋄ery┊ tale⋄ m│21│00000120│ 6f 72 65 20 73 77 00 65 ┊ 65 74 6c 79 20 74 68 00 │ore sw⋄e┊etly th⋄│22│00000130│ 61 6e 20 6f 75 72 20 72 ┊ 00 68 79 6d 65 3a 0a 57 │an our r┊⋄hyme:_W│23│00000140│ 68 00 61 74 20 6c 65 61 ┊ 66 2d 00 66 72 69 6e 67 │h⋄at lea┊f-⋄fring│24│00000150│ 27 64 20 00 6c 65 67 65 ┊ 6e 64 20 68 00 61 75 6e │'d ⋄lege┊nd h⋄aun│25│00000160│ 74 73 20 61 62 04 6f 75 ┊ 01 66 79 20 73 68 61 04 │ts ab•ou┊•fy sha•│26│00000170│ 70 65 05 63 4f 66 20 64 ┊ 65 00 69 74 69 65 73 20 │pe•cOf d┊e⋄ities │27│00000180│ 6f 72 41 01 62 74 61 6c ┊ 73 2c 01 0c 6f c0 66 20 │orA•btal┊s,•_o×f │28│00000190│ 62 6f 74 68 06 e9 05 01 ┊ 00 49 6e 20 54 65 6d 70 │both•×••┊⋄In Temp│29│000001a0│ 65 01 01 24 74 68 65 20 ┊ 64 61 6c 01 01 3d 66 20 │e••$the ┊dal••=f │30│000001b0│ 41 72 63 61 64 8c 79 3f ┊ 05 30 02 91 6d 65 6e 01 │Arcad×y?┊•0•×men•│31│000001c0│ 28 00 67 6f 64 73 20 61 ┊ 72 65 11 01 31 73 65 3f │(⋄gods a┊re••1se?│I’ve cut it off at 30 lines because we don’t really need to see the whole thing. Again, we see 02 00 00 00 for the row ID, the title as a plain string followed by the jsonb blob then the country ID – again eb 00 00 00 – next we have the 4-byte varlena metadata 2f 1a 00 00 before we get into the data.
You’ll notice that the data looks a little bit different this time – it starts off looking normal but over time more and more of the text turns into gibberish! This is because Postgres has decided that the string is sufficiently long that it needs compressing to fit it into the page. What you’re looking at here is the compressed version of the poem. Compression is a fascinating topic which I could do a whole blog series on in itself. Without going into too much detail, Postgres uses the pglz compression algorithm which is an implementation of the LZ compression algorithm. This uses a simple history table to refer back to previously seen values instead of repeating them. For instance, the poem starts Thou still... on the first line and Thou foster-child... on the second line, but you can see that the second Thou has been replaced with 03 01 02 31 which encodes the previously seen instance of Thou , thereby saving 1 byte. (Okay, not that impressive in this case, but it obviously reduces space over the course of the whole poem a lot!)
This explains why the row was only 1,844 bytes long when the poem itself is 2,442 characters.
Finally, let’s look at The Waste Land:
1$ print-cw-data 'The Waste Land'2┌────────┬─────────────────────────┬─────────────────────────┬────────┬────────┐3│00000000│ 03 00 00 00 1f 54 68 65 ┊ 20 57 61 73 74 65 20 4c │•⋄⋄⋄•The┊ Waste L│4│00000010│ 61 6e 64 db 01 00 00 40 ┊ 64 00 00 d0 03 00 00 20 │andו⋄⋄@┊d⋄⋄ו⋄⋄ │5│00000020│ 04 00 00 80 0a 00 00 00 ┊ 0a 00 00 00 1d 00 00 00 │•⋄⋄×_⋄⋄⋄┊_⋄⋄⋄•⋄⋄⋄│6│00000030│ 0b 00 00 10 08 00 00 10 ┊ 6e 61 6d 65 62 69 72 74 │•⋄⋄••⋄⋄•┊namebirt│7│00000040│ 68 5f 79 65 61 72 64 65 ┊ 61 74 68 5f 79 65 61 72 │h_yearde┊ath_year│8│00000050│ 45 6c 69 6f 74 2c 20 54 ┊ 2e 20 53 2e 20 28 54 68 │Eliot, T┊. S. (Th│9│00000060│ 6f 6d 61 73 20 53 74 65 ┊ 61 72 6e 73 29 00 00 00 │omas Ste┊arns)⋄⋄⋄│10│00000070│ 20 00 00 00 00 80 60 07 ┊ 20 00 00 00 00 80 ad 07 │ ⋄⋄⋄⋄×`•┊ ⋄⋄⋄⋄×ו│11│00000080│ ec 00 00 00 01 12 ed 4e ┊ 00 00 24 2d 00 00 ff 66 │×⋄⋄⋄••×N┊⋄⋄$-⋄⋄×f│12│00000090│ 00 00 d5 61 00 00 ┊ │⋄⋄×a⋄⋄ ┊ │13└────────┴─────────────────────────┴─────────────────────────┴────────┴────────┘This row is puny by comparison. It’s got the usual ID, title, authors and country ID (this time ec 00 00 00 = 236 = USA), then 01 12 ed 4e for the varlena metadata3, but then instead of the poem it’s just got 14 bytes of gibbberish – where’s it gone‽
Let’s talk about TOAST
I’ve managed to go all the main thus far without actually explaining what anything has got to do with TOAST or even what TOAST is, but now I can’t avoid it.
TOAST = The Oversized-Attribute Storage Technique
This is the name that Postgres gives its technique for handling these pesky values that just won’t fit into their page like a good value. We’ve seen it in action already, we just didn’t know that that’s what it was called!
These three poems have been carefully selected4 to showcase the two TOAST tools that Postgres uses: compression and out-of-lining. These tools can be used on many variable length field, not just strings like our poems. For instance, bytea and jsonb values are commonly “TOAST-ed” as well.
What is this “out-of-lining”, I hear you say? It’s precisely what it sounds like: Postgres takes the value out of the line that the rest of the row sits in, and puts it a separate relation where it can really think about its actions until its small enough to come back inside the main heap file.
It’s still being stored somewhere, so how do we track down where it’s snuck off to? This is where we turn to our old friend pg_class:
1blogdb=# select oid, relname, relfilenode, reltoastrelid2blogdb-# from pg_class where relname = 'creative_works';3 oid | relname | relfilenode | reltoastrelid | relnamespace4-------+----------------+-------------+---------------+--------------5 25042 | creative_works | 26735 | 25045 | 22006(1 row)Ahah, there’s a column called reltoastrelid that points from the main relation to the toast relation – let’s follow it.
1blogdb=# select oid, relname, relfilenode, reltoastrelid, relnamespace2blogdb-# from pg_class where oid = (3blogdb-# select reltoastrelid from pg_class where relname = 'creative_works'4blogdb-# );5 oid | relname | relfilenode | reltoastrelid | relnamespace6-------+----------------+-------------+---------------+--------------7 25045 | pg_toast_25042 | 26738 | 0 | 998(1 row)You can see that the name of the toast table is just pg_toast_{main table oid}.
You might be thinking “I’ve never seen this pg_toast_25042 table before in my schema, where is it hiding? Notice that the relnamespace for the main table and the toast table is different – this means that the TOAST table is in a different schema. We find can out the name of the schema by looking at pg_catalog.pg_namespace:
1blogdb=# select * from pg_catalog.pg_namespace;2 oid | nspname | nspowner | nspacl3-------+--------------------+----------+---------------------------------------------------------------4 99 | pg_toast | 10 |5 11 | pg_catalog | 10 | {postgres=UC/postgres,=U/postgres}6 2200 | public | 6171 | {pg_database_owner=UC/pg_database_owner,=U/pg_database_owner}7 13212 | information_schema | 10 | {postgres=UC/postgres,=U/postgres}8 26359 | pg_temp_3 | 10 |9 26360 | pg_toast_temp_3 | 10 |10(6 rows)So the main table is in the default public schema (2200) while the pg_toast_25042 table is in the pg_toast schema (99). Now that we know that, we can go back to our friend pageinspect to dig into the toast table:
1blogdb=# select lp, lp_off, lp_flags, lp_len, t_xmin, t_xmax, t_field3, t_ctid, t_infomask2, t_infomask, t_hoff, t_bits, t_oid2blogdb-# from heap_page_items(get_raw_page('pg_toast.pg_toast_25042', 0));3 lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid4----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------5 1 | 6160 | 1 | 2032 | 1136 | 0 | 5 | (0,1) | 3 | 2050 | 24 | |6 2 | 4128 | 1 | 2032 | 1136 | 0 | 5 | (0,2) | 3 | 2050 | 24 | |7 3 | 2096 | 1 | 2032 | 1136 | 0 | 5 | (0,3) | 3 | 2050 | 24 | |8 4 | 64 | 1 | 2032 | 1136 | 0 | 5 | (0,4) | 3 | 2050 | 24 | |9(4 rows)10
11blogdb=# select lp, lp_off, lp_flags, lp_len, t_xmin, t_xmax, t_field3, t_ctid, t_infomask2, t_infomask, t_hoff, t_bits, t_oid12blogdb-# from heap_page_items(get_raw_page('pg_toast.pg_toast_25042', 1));13 lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid14----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------15 1 | 6160 | 1 | 2032 | 1136 | 0 | 5 | (1,1) | 3 | 2050 | 24 | |16 2 | 4544 | 1 | 1612 | 1136 | 0 | 5 | (1,2) | 3 | 2050 | 24 | |17(2 rows)Not only has our poem been split into multiple pages, it’s been split into multiple tuples within each page!
In our case, we’ve only got one out-of-lined value, so linking the attribute to the toast tuples is fairly simple, but in general this isn’t the case. So how do we actually link the data in the main table tuple and the out-of-lined data in the toast table?
Use the source, Luke
When you get to this level of detail, it’s easier to just read the source code rather than trying to cobble together bits of information from other sources, so let’s take a quick peek at the Postgres source code for this stuff.
PostgreSQL source code as reproduced here is copyrighted by PostgreSQL Global Development Group under the PostgreSQL License.
The function that “de-TOASTs” data is detoast_attr() in the src/backend/access/common/detoast.c file. It’s not that long, but we’re only thinking about the first if block at the moment:
103 collapsed lines
1/*-------------------------------------------------------------------------2 *3 * detoast.c4 * Retrieve compressed or external variable size attributes.5 *6 * Copyright (c) 2000-2024, PostgreSQL Global Development Group7 *8 * IDENTIFICATION9 * src/backend/access/common/detoast.c10 *11 *-------------------------------------------------------------------------12 */13
14#include "postgres.h"15
16#include "access/detoast.h"17#include "access/table.h"18#include "access/tableam.h"19#include "access/toast_internals.h"20#include "common/int.h"21#include "common/pg_lzcompress.h"22#include "utils/expandeddatum.h"23#include "utils/rel.h"24
25static struct varlena *toast_fetch_datum(struct varlena *attr);26static struct varlena *toast_fetch_datum_slice(struct varlena *attr,27 int32 sliceoffset,28 int32 slicelength);29static struct varlena *toast_decompress_datum(struct varlena *attr);30static struct varlena *toast_decompress_datum_slice(struct varlena *attr, int32 slicelength);31
32/* ----------33 * detoast_external_attr -34 *35 * Public entry point to get back a toasted value from36 * external source (possibly still in compressed format).37 *38 * This will return a datum that contains all the data internally, ie, not39 * relying on external storage or memory, but it can still be compressed or40 * have a short header. Note some callers assume that if the input is an41 * EXTERNAL datum, the result will be a pfree'able chunk.42 * ----------43 */44struct varlena *45detoast_external_attr(struct varlena *attr)46{47 struct varlena *result;48
49 if (VARATT_IS_EXTERNAL_ONDISK(attr))50 {51 /*52 * This is an external stored plain value53 */54 result = toast_fetch_datum(attr);55 }56 else if (VARATT_IS_EXTERNAL_INDIRECT(attr))57 {58 /*59 * This is an indirect pointer --- dereference it60 */61 struct varatt_indirect redirect;62
63 VARATT_EXTERNAL_GET_POINTER(redirect, attr);64 attr = (struct varlena *) redirect.pointer;65
66 /* nested indirect Datums aren't allowed */67 Assert(!VARATT_IS_EXTERNAL_INDIRECT(attr));68
69 /* recurse if value is still external in some other way */70 if (VARATT_IS_EXTERNAL(attr))71 return detoast_external_attr(attr);72
73 /*74 * Copy into the caller's memory context, in case caller tries to75 * pfree the result.76 */77 result = (struct varlena *) palloc(VARSIZE_ANY(attr));78 memcpy(result, attr, VARSIZE_ANY(attr));79 }80 else if (VARATT_IS_EXTERNAL_EXPANDED(attr))81 {82 /*83 * This is an expanded-object pointer --- get flat format84 */85 ExpandedObjectHeader *eoh;86 Size resultsize;87
88 eoh = DatumGetEOHP(PointerGetDatum(attr));89 resultsize = EOH_get_flat_size(eoh);90 result = (struct varlena *) palloc(resultsize);91 EOH_flatten_into(eoh, (void *) result, resultsize);92 }93 else94 {95 /*96 * This is a plain value inside of the main tuple - why am I called?97 */98 result = attr;99 }100
101 return result;102}103
104
105/* ----------106 * detoast_attr -107 *108 * Public entry point to get back a toasted value from compression109 * or external storage. The result is always non-extended varlena form.110 *111 * Note some callers assume that if the input is an EXTERNAL or COMPRESSED112 * datum, the result will be a pfree'able chunk.113 * ----------114 */115struct varlena *116detoast_attr(struct varlena *attr)117{118 if (VARATT_IS_EXTERNAL_ONDISK(attr))119 {120 /*121 * This is an externally stored datum --- fetch it back from there122 */123 attr = toast_fetch_datum(attr);124 /* If it's compressed, decompress it */125 if (VARATT_IS_COMPRESSED(attr))126 {127 struct varlena *tmp = attr;128
129 attr = toast_decompress_datum(tmp);130 pfree(tmp);131 }132 }133 else if (VARATT_IS_EXTERNAL_INDIRECT(attr))134 {135 /*136 * This is an indirect pointer --- dereference it137 */138 struct varatt_indirect redirect;139
140 VARATT_EXTERNAL_GET_POINTER(redirect, attr);141 attr = (struct varlena *) redirect.pointer;142
143 /* nested indirect Datums aren't allowed */144 Assert(!VARATT_IS_EXTERNAL_INDIRECT(attr));145
146 /* recurse in case value is still extended in some other way */147 attr = detoast_attr(attr);148
149 /* if it isn't, we'd better copy it */150 if (attr == (struct varlena *) redirect.pointer)151 {152 struct varlena *result;153
154 result = (struct varlena *) palloc(VARSIZE_ANY(attr));155 memcpy(result, attr, VARSIZE_ANY(attr));156 attr = result;157 }158 }159 else if (VARATT_IS_EXTERNAL_EXPANDED(attr))160 {161 /*162 * This is an expanded-object pointer --- get flat format163 */164 attr = detoast_external_attr(attr);165 /* flatteners are not allowed to produce compressed/short output */166 Assert(!VARATT_IS_EXTENDED(attr));167 }168 else if (VARATT_IS_COMPRESSED(attr))169 {170 /*171 * This is a compressed value inside of the main tuple172 */173 attr = toast_decompress_datum(attr);174 }175 else if (VARATT_IS_SHORT(attr))176 {177 /*178 * This is a short-header varlena --- convert to 4-byte header format179 */180 Size data_size = VARSIZE_SHORT(attr) - VARHDRSZ_SHORT;181 Size new_size = data_size + VARHDRSZ;182 struct varlena *new_attr;183
184 new_attr = (struct varlena *) palloc(new_size);185 SET_VARSIZE(new_attr, new_size);186 memcpy(VARDATA(new_attr), VARDATA_SHORT(attr), data_size);187 attr = new_attr;188 }189
190 return attr;191}192
454 collapsed lines
193
194/* ----------195 * detoast_attr_slice -196 *197 * Public entry point to get back part of a toasted value198 * from compression or external storage.199 *200 * sliceoffset is where to start (zero or more)201 * If slicelength < 0, return everything beyond sliceoffset202 * ----------203 */204struct varlena *205detoast_attr_slice(struct varlena *attr,206 int32 sliceoffset, int32 slicelength)207{208 struct varlena *preslice;209 struct varlena *result;210 char *attrdata;211 int32 slicelimit;212 int32 attrsize;213
214 if (sliceoffset < 0)215 elog(ERROR, "invalid sliceoffset: %d", sliceoffset);216
217 /*218 * Compute slicelimit = offset + length, or -1 if we must fetch all of the219 * value. In case of integer overflow, we must fetch all.220 */221 if (slicelength < 0)222 slicelimit = -1;223 else if (pg_add_s32_overflow(sliceoffset, slicelength, &slicelimit))224 slicelength = slicelimit = -1;225
226 if (VARATT_IS_EXTERNAL_ONDISK(attr))227 {228 struct varatt_external toast_pointer;229
230 VARATT_EXTERNAL_GET_POINTER(toast_pointer, attr);231
232 /* fast path for non-compressed external datums */233 if (!VARATT_EXTERNAL_IS_COMPRESSED(toast_pointer))234 return toast_fetch_datum_slice(attr, sliceoffset, slicelength);235
236 /*237 * For compressed values, we need to fetch enough slices to decompress238 * at least the requested part (when a prefix is requested).239 * Otherwise, just fetch all slices.240 */241 if (slicelimit >= 0)242 {243 int32 max_size = VARATT_EXTERNAL_GET_EXTSIZE(toast_pointer);244
245 /*246 * Determine maximum amount of compressed data needed for a prefix247 * of a given length (after decompression).248 *249 * At least for now, if it's LZ4 data, we'll have to fetch the250 * whole thing, because there doesn't seem to be an API call to251 * determine how much compressed data we need to be sure of being252 * able to decompress the required slice.253 */254 if (VARATT_EXTERNAL_GET_COMPRESS_METHOD(toast_pointer) ==255 TOAST_PGLZ_COMPRESSION_ID)256 max_size = pglz_maximum_compressed_size(slicelimit, max_size);257
258 /*259 * Fetch enough compressed slices (compressed marker will get set260 * automatically).261 */262 preslice = toast_fetch_datum_slice(attr, 0, max_size);263 }264 else265 preslice = toast_fetch_datum(attr);266 }267 else if (VARATT_IS_EXTERNAL_INDIRECT(attr))268 {269 struct varatt_indirect redirect;270
271 VARATT_EXTERNAL_GET_POINTER(redirect, attr);272
273 /* nested indirect Datums aren't allowed */274 Assert(!VARATT_IS_EXTERNAL_INDIRECT(redirect.pointer));275
276 return detoast_attr_slice(redirect.pointer,277 sliceoffset, slicelength);278 }279 else if (VARATT_IS_EXTERNAL_EXPANDED(attr))280 {281 /* pass it off to detoast_external_attr to flatten */282 preslice = detoast_external_attr(attr);283 }284 else285 preslice = attr;286
287 Assert(!VARATT_IS_EXTERNAL(preslice));288
289 if (VARATT_IS_COMPRESSED(preslice))290 {291 struct varlena *tmp = preslice;292
293 /* Decompress enough to encompass the slice and the offset */294 if (slicelimit >= 0)295 preslice = toast_decompress_datum_slice(tmp, slicelimit);296 else297 preslice = toast_decompress_datum(tmp);298
299 if (tmp != attr)300 pfree(tmp);301 }302
303 if (VARATT_IS_SHORT(preslice))304 {305 attrdata = VARDATA_SHORT(preslice);306 attrsize = VARSIZE_SHORT(preslice) - VARHDRSZ_SHORT;307 }308 else309 {310 attrdata = VARDATA(preslice);311 attrsize = VARSIZE(preslice) - VARHDRSZ;312 }313
314 /* slicing of datum for compressed cases and plain value */315
316 if (sliceoffset >= attrsize)317 {318 sliceoffset = 0;319 slicelength = 0;320 }321 else if (slicelength < 0 || slicelimit > attrsize)322 slicelength = attrsize - sliceoffset;323
324 result = (struct varlena *) palloc(slicelength + VARHDRSZ);325 SET_VARSIZE(result, slicelength + VARHDRSZ);326
327 memcpy(VARDATA(result), attrdata + sliceoffset, slicelength);328
329 if (preslice != attr)330 pfree(preslice);331
332 return result;333}334
335/* ----------336 * toast_fetch_datum -337 *338 * Reconstruct an in memory Datum from the chunks saved339 * in the toast relation340 * ----------341 */342static struct varlena *343toast_fetch_datum(struct varlena *attr)344{345 Relation toastrel;346 struct varlena *result;347 struct varatt_external toast_pointer;348 int32 attrsize;349
350 if (!VARATT_IS_EXTERNAL_ONDISK(attr))351 elog(ERROR, "toast_fetch_datum shouldn't be called for non-ondisk datums");352
353 /* Must copy to access aligned fields */354 VARATT_EXTERNAL_GET_POINTER(toast_pointer, attr);355
356 attrsize = VARATT_EXTERNAL_GET_EXTSIZE(toast_pointer);357
358 result = (struct varlena *) palloc(attrsize + VARHDRSZ);359
360 if (VARATT_EXTERNAL_IS_COMPRESSED(toast_pointer))361 SET_VARSIZE_COMPRESSED(result, attrsize + VARHDRSZ);362 else363 SET_VARSIZE(result, attrsize + VARHDRSZ);364
365 if (attrsize == 0)366 return result; /* Probably shouldn't happen, but just in367 * case. */368
369 /*370 * Open the toast relation and its indexes371 */372 toastrel = table_open(toast_pointer.va_toastrelid, AccessShareLock);373
374 /* Fetch all chunks */375 table_relation_fetch_toast_slice(toastrel, toast_pointer.va_valueid,376 attrsize, 0, attrsize, result);377
378 /* Close toast table */379 table_close(toastrel, AccessShareLock);380
381 return result;382}383
384/* ----------385 * toast_fetch_datum_slice -386 *387 * Reconstruct a segment of a Datum from the chunks saved388 * in the toast relation389 *390 * Note that this function supports non-compressed external datums391 * and compressed external datums (in which case the requested slice392 * has to be a prefix, i.e. sliceoffset has to be 0).393 * ----------394 */395static struct varlena *396toast_fetch_datum_slice(struct varlena *attr, int32 sliceoffset,397 int32 slicelength)398{399 Relation toastrel;400 struct varlena *result;401 struct varatt_external toast_pointer;402 int32 attrsize;403
404 if (!VARATT_IS_EXTERNAL_ONDISK(attr))405 elog(ERROR, "toast_fetch_datum_slice shouldn't be called for non-ondisk datums");406
407 /* Must copy to access aligned fields */408 VARATT_EXTERNAL_GET_POINTER(toast_pointer, attr);409
410 /*411 * It's nonsense to fetch slices of a compressed datum unless when it's a412 * prefix -- this isn't lo_* we can't return a compressed datum which is413 * meaningful to toast later.414 */415 Assert(!VARATT_EXTERNAL_IS_COMPRESSED(toast_pointer) || 0 == sliceoffset);416
417 attrsize = VARATT_EXTERNAL_GET_EXTSIZE(toast_pointer);418
419 if (sliceoffset >= attrsize)420 {421 sliceoffset = 0;422 slicelength = 0;423 }424
425 /*426 * When fetching a prefix of a compressed external datum, account for the427 * space required by va_tcinfo, which is stored at the beginning as an428 * int32 value.429 */430 if (VARATT_EXTERNAL_IS_COMPRESSED(toast_pointer) && slicelength > 0)431 slicelength = slicelength + sizeof(int32);432
433 /*434 * Adjust length request if needed. (Note: our sole caller,435 * detoast_attr_slice, protects us against sliceoffset + slicelength436 * overflowing.)437 */438 if (((sliceoffset + slicelength) > attrsize) || slicelength < 0)439 slicelength = attrsize - sliceoffset;440
441 result = (struct varlena *) palloc(slicelength + VARHDRSZ);442
443 if (VARATT_EXTERNAL_IS_COMPRESSED(toast_pointer))444 SET_VARSIZE_COMPRESSED(result, slicelength + VARHDRSZ);445 else446 SET_VARSIZE(result, slicelength + VARHDRSZ);447
448 if (slicelength == 0)449 return result; /* Can save a lot of work at this point! */450
451 /* Open the toast relation */452 toastrel = table_open(toast_pointer.va_toastrelid, AccessShareLock);453
454 /* Fetch all chunks */455 table_relation_fetch_toast_slice(toastrel, toast_pointer.va_valueid,456 attrsize, sliceoffset, slicelength,457 result);458
459 /* Close toast table */460 table_close(toastrel, AccessShareLock);461
462 return result;463}464
465/* ----------466 * toast_decompress_datum -467 *468 * Decompress a compressed version of a varlena datum469 */470static struct varlena *471toast_decompress_datum(struct varlena *attr)472{473 ToastCompressionId cmid;474
475 Assert(VARATT_IS_COMPRESSED(attr));476
477 /*478 * Fetch the compression method id stored in the compression header and479 * decompress the data using the appropriate decompression routine.480 */481 cmid = TOAST_COMPRESS_METHOD(attr);482 switch (cmid)483 {484 case TOAST_PGLZ_COMPRESSION_ID:485 return pglz_decompress_datum(attr);486 case TOAST_LZ4_COMPRESSION_ID:487 return lz4_decompress_datum(attr);488 default:489 elog(ERROR, "invalid compression method id %d", cmid);490 return NULL; /* keep compiler quiet */491 }492}493
494
495/* ----------496 * toast_decompress_datum_slice -497 *498 * Decompress the front of a compressed version of a varlena datum.499 * offset handling happens in detoast_attr_slice.500 * Here we just decompress a slice from the front.501 */502static struct varlena *503toast_decompress_datum_slice(struct varlena *attr, int32 slicelength)504{505 ToastCompressionId cmid;506
507 Assert(VARATT_IS_COMPRESSED(attr));508
509 /*510 * Some callers may pass a slicelength that's more than the actual511 * decompressed size. If so, just decompress normally. This avoids512 * possibly allocating a larger-than-necessary result object, and may be513 * faster and/or more robust as well. Notably, some versions of liblz4514 * have been seen to give wrong results if passed an output size that is515 * more than the data's true decompressed size.516 */517 if ((uint32) slicelength >= TOAST_COMPRESS_EXTSIZE(attr))518 return toast_decompress_datum(attr);519
520 /*521 * Fetch the compression method id stored in the compression header and522 * decompress the data slice using the appropriate decompression routine.523 */524 cmid = TOAST_COMPRESS_METHOD(attr);525 switch (cmid)526 {527 case TOAST_PGLZ_COMPRESSION_ID:528 return pglz_decompress_datum_slice(attr, slicelength);529 case TOAST_LZ4_COMPRESSION_ID:530 return lz4_decompress_datum_slice(attr, slicelength);531 default:532 elog(ERROR, "invalid compression method id %d", cmid);533 return NULL; /* keep compiler quiet */534 }535}536
537/* ----------538 * toast_raw_datum_size -539 *540 * Return the raw (detoasted) size of a varlena datum541 * (including the VARHDRSZ header)542 * ----------543 */544Size545toast_raw_datum_size(Datum value)546{547 struct varlena *attr = (struct varlena *) DatumGetPointer(value);548 Size result;549
550 if (VARATT_IS_EXTERNAL_ONDISK(attr))551 {552 /* va_rawsize is the size of the original datum -- including header */553 struct varatt_external toast_pointer;554
555 VARATT_EXTERNAL_GET_POINTER(toast_pointer, attr);556 result = toast_pointer.va_rawsize;557 }558 else if (VARATT_IS_EXTERNAL_INDIRECT(attr))559 {560 struct varatt_indirect toast_pointer;561
562 VARATT_EXTERNAL_GET_POINTER(toast_pointer, attr);563
564 /* nested indirect Datums aren't allowed */565 Assert(!VARATT_IS_EXTERNAL_INDIRECT(toast_pointer.pointer));566
567 return toast_raw_datum_size(PointerGetDatum(toast_pointer.pointer));568 }569 else if (VARATT_IS_EXTERNAL_EXPANDED(attr))570 {571 result = EOH_get_flat_size(DatumGetEOHP(value));572 }573 else if (VARATT_IS_COMPRESSED(attr))574 {575 /* here, va_rawsize is just the payload size */576 result = VARDATA_COMPRESSED_GET_EXTSIZE(attr) + VARHDRSZ;577 }578 else if (VARATT_IS_SHORT(attr))579 {580 /*581 * we have to normalize the header length to VARHDRSZ or else the582 * callers of this function will be confused.583 */584 result = VARSIZE_SHORT(attr) - VARHDRSZ_SHORT + VARHDRSZ;585 }586 else587 {588 /* plain untoasted datum */589 result = VARSIZE(attr);590 }591 return result;592}593
594/* ----------595 * toast_datum_size596 *597 * Return the physical storage size (possibly compressed) of a varlena datum598 * ----------599 */600Size601toast_datum_size(Datum value)602{603 struct varlena *attr = (struct varlena *) DatumGetPointer(value);604 Size result;605
606 if (VARATT_IS_EXTERNAL_ONDISK(attr))607 {608 /*609 * Attribute is stored externally - return the extsize whether610 * compressed or not. We do not count the size of the toast pointer611 * ... should we?612 */613 struct varatt_external toast_pointer;614
615 VARATT_EXTERNAL_GET_POINTER(toast_pointer, attr);616 result = VARATT_EXTERNAL_GET_EXTSIZE(toast_pointer);617 }618 else if (VARATT_IS_EXTERNAL_INDIRECT(attr))619 {620 struct varatt_indirect toast_pointer;621
622 VARATT_EXTERNAL_GET_POINTER(toast_pointer, attr);623
624 /* nested indirect Datums aren't allowed */625 Assert(!VARATT_IS_EXTERNAL_INDIRECT(attr));626
627 return toast_datum_size(PointerGetDatum(toast_pointer.pointer));628 }629 else if (VARATT_IS_EXTERNAL_EXPANDED(attr))630 {631 result = EOH_get_flat_size(DatumGetEOHP(value));632 }633 else if (VARATT_IS_SHORT(attr))634 {635 result = VARSIZE_SHORT(attr);636 }637 else638 {639 /*640 * Attribute is stored inline either compressed or not, just calculate641 * the size of the datum in either case.642 */643 result = VARSIZE(attr);644 }645 return result;646}The rest of the function goes on to check the other TOAST cases which aren’t particularly relevant to us right now. The important thing is that VARATT_IS_EXTERNAL_ONDISK() is a macro that tells you whether a varlena struct refers to an out-of-line (a.k.a. external) value stored on disk (i.e. in a TOAST table). You can also see that the out-of-line attributes can also be compressed within the external TOAST table.
Remember that varlena is the struct that holds the main table data for a variable length attribute – in our case that’s the 18 bytes of gibberish we saw earlier. To understand these weird 18 bytes and to understand varlena more broadly, we need to look at the src/include/varatt.h file in the Postgres codebase – I’ve highlighted the most important bits and collapsed the bits we don’t really care about:
16 collapsed lines
1/*-------------------------------------------------------------------------2 *3 * varatt.h4 * variable-length datatypes (TOAST support)5 *6 *7 * Portions Copyright (c) 1996-2024, PostgreSQL Global Development Group8 * Portions Copyright (c) 1995, Regents of the University of California9 *10 * src/include/varatt.h11 *12 *-------------------------------------------------------------------------13 */14
15#ifndef VARATT_H16#define VARATT_H17
18/*19 * struct varatt_external is a traditional "TOAST pointer", that is, the20 * information needed to fetch a Datum stored out-of-line in a TOAST table.21 * The data is compressed if and only if the external size stored in22 * va_extinfo is less than va_rawsize - VARHDRSZ.23 *24 * This struct must not contain any padding, because we sometimes compare25 * these pointers using memcmp.26 *27 * Note that this information is stored unaligned within actual tuples, so28 * you need to memcpy from the tuple into a local struct variable before29 * you can look at these fields! (The reason we use memcmp is to avoid30 * having to do that just to detect equality of two TOAST pointers...)31 */32typedef struct varatt_external33{34 int32 va_rawsize; /* Original data size (includes header) */35 uint32 va_extinfo; /* External saved size (without header) and36 * compression method */37 Oid va_valueid; /* Unique ID of value within TOAST table */38 Oid va_toastrelid; /* RelID of TOAST table containing it */39} varatt_external;40
37 collapsed lines
41/*42 * These macros define the "saved size" portion of va_extinfo. Its remaining43 * two high-order bits identify the compression method.44 */45#define VARLENA_EXTSIZE_BITS 3046#define VARLENA_EXTSIZE_MASK ((1U << VARLENA_EXTSIZE_BITS) - 1)47
48/*49 * struct varatt_indirect is a "TOAST pointer" representing an out-of-line50 * Datum that's stored in memory, not in an external toast relation.51 * The creator of such a Datum is entirely responsible that the referenced52 * storage survives for as long as referencing pointer Datums can exist.53 *54 * Note that just as for struct varatt_external, this struct is stored55 * unaligned within any containing tuple.56 */57typedef struct varatt_indirect58{59 struct varlena *pointer; /* Pointer to in-memory varlena */60} varatt_indirect;61
62/*63 * struct varatt_expanded is a "TOAST pointer" representing an out-of-line64 * Datum that is stored in memory, in some type-specific, not necessarily65 * physically contiguous format that is convenient for computation not66 * storage. APIs for this, in particular the definition of struct67 * ExpandedObjectHeader, are in src/include/utils/expandeddatum.h.68 *69 * Note that just as for struct varatt_external, this struct is stored70 * unaligned within any containing tuple.71 */72typedef struct ExpandedObjectHeader ExpandedObjectHeader;73
74typedef struct varatt_expanded75{76 ExpandedObjectHeader *eohptr;77} varatt_expanded;78
79/*80 * Type tag for the various sorts of "TOAST pointer" datums. The peculiar81 * value for VARTAG_ONDISK comes from a requirement for on-disk compatibility82 * with a previous notion that the tag field was the pointer datum's length.83 */84typedef enum vartag_external85{86 VARTAG_INDIRECT = 1,87 VARTAG_EXPANDED_RO = 2,88 VARTAG_EXPANDED_RW = 3,89 VARTAG_ONDISK = 1890} vartag_external;91
9 collapsed lines
92/* this test relies on the specific tag values above */93#define VARTAG_IS_EXPANDED(tag) \94 (((tag) & ~1) == VARTAG_EXPANDED_RO)95
96#define VARTAG_SIZE(tag) \97 ((tag) == VARTAG_INDIRECT ? sizeof(varatt_indirect) : \98 VARTAG_IS_EXPANDED(tag) ? sizeof(varatt_expanded) : \99 (tag) == VARTAG_ONDISK ? sizeof(varatt_external) : \100 (AssertMacro(false), 0))101
102/*103 * These structs describe the header of a varlena object that may have been104 * TOASTed. Generally, don't reference these structs directly, but use the105 * macros below.106 *107 * We use separate structs for the aligned and unaligned cases because the108 * compiler might otherwise think it could generate code that assumes109 * alignment while touching fields of a 1-byte-header varlena.110 */111typedef union112{113 struct /* Normal varlena (4-byte length) */114 {115 uint32 va_header;116 char va_data[FLEXIBLE_ARRAY_MEMBER];117 } va_4byte;118 struct /* Compressed-in-line format */119 {120 uint32 va_header;121 uint32 va_tcinfo; /* Original data size (excludes header) and122 * compression method; see va_extinfo */123 char va_data[FLEXIBLE_ARRAY_MEMBER]; /* Compressed data */124 } va_compressed;125} varattrib_4b;126
127typedef struct128{129 uint8 va_header;130 char va_data[FLEXIBLE_ARRAY_MEMBER]; /* Data begins here */131} varattrib_1b;132
133/* TOAST pointers are a subset of varattrib_1b with an identifying tag byte */134typedef struct135{136 uint8 va_header; /* Always 0x80 or 0x01 */137 uint8 va_tag; /* Type of datum */138 char va_data[FLEXIBLE_ARRAY_MEMBER]; /* Type-specific data */139} varattrib_1b_e;140
69 collapsed lines
141/*142 * Bit layouts for varlena headers on big-endian machines:143 *144 * 00xxxxxx 4-byte length word, aligned, uncompressed data (up to 1G)145 * 01xxxxxx 4-byte length word, aligned, *compressed* data (up to 1G)146 * 10000000 1-byte length word, unaligned, TOAST pointer147 * 1xxxxxxx 1-byte length word, unaligned, uncompressed data (up to 126b)148 *149 * Bit layouts for varlena headers on little-endian machines:150 *151 * xxxxxx00 4-byte length word, aligned, uncompressed data (up to 1G)152 * xxxxxx10 4-byte length word, aligned, *compressed* data (up to 1G)153 * 00000001 1-byte length word, unaligned, TOAST pointer154 * xxxxxxx1 1-byte length word, unaligned, uncompressed data (up to 126b)155 *156 * The "xxx" bits are the length field (which includes itself in all cases).157 * In the big-endian case we mask to extract the length, in the little-endian158 * case we shift. Note that in both cases the flag bits are in the physically159 * first byte. Also, it is not possible for a 1-byte length word to be zero;160 * this lets us disambiguate alignment padding bytes from the start of an161 * unaligned datum. (We now *require* pad bytes to be filled with zero!)162 *163 * In TOAST pointers the va_tag field (see varattrib_1b_e) is used to discern164 * the specific type and length of the pointer datum.165 */166
167/*168 * Endian-dependent macros. These are considered internal --- use the169 * external macros below instead of using these directly.170 *171 * Note: IS_1B is true for external toast records but VARSIZE_1B will return 0172 * for such records. Hence you should usually check for IS_EXTERNAL before173 * checking for IS_1B.174 */175
176#ifdef WORDS_BIGENDIAN177
178#define VARATT_IS_4B(PTR) \179 ((((varattrib_1b *) (PTR))->va_header & 0x80) == 0x00)180#define VARATT_IS_4B_U(PTR) \181 ((((varattrib_1b *) (PTR))->va_header & 0xC0) == 0x00)182#define VARATT_IS_4B_C(PTR) \183 ((((varattrib_1b *) (PTR))->va_header & 0xC0) == 0x40)184#define VARATT_IS_1B(PTR) \185 ((((varattrib_1b *) (PTR))->va_header & 0x80) == 0x80)186#define VARATT_IS_1B_E(PTR) \187 ((((varattrib_1b *) (PTR))->va_header) == 0x80)188#define VARATT_NOT_PAD_BYTE(PTR) \189 (*((uint8 *) (PTR)) != 0)190
191/* VARSIZE_4B() should only be used on known-aligned data */192#define VARSIZE_4B(PTR) \193 (((varattrib_4b *) (PTR))->va_4byte.va_header & 0x3FFFFFFF)194#define VARSIZE_1B(PTR) \195 (((varattrib_1b *) (PTR))->va_header & 0x7F)196#define VARTAG_1B_E(PTR) \197 (((varattrib_1b_e *) (PTR))->va_tag)198
199#define SET_VARSIZE_4B(PTR,len) \200 (((varattrib_4b *) (PTR))->va_4byte.va_header = (len) & 0x3FFFFFFF)201#define SET_VARSIZE_4B_C(PTR,len) \202 (((varattrib_4b *) (PTR))->va_4byte.va_header = ((len) & 0x3FFFFFFF) | 0x40000000)203#define SET_VARSIZE_1B(PTR,len) \204 (((varattrib_1b *) (PTR))->va_header = (len) | 0x80)205#define SET_VARTAG_1B_E(PTR,tag) \206 (((varattrib_1b_e *) (PTR))->va_header = 0x80, \207 ((varattrib_1b_e *) (PTR))->va_tag = (tag))208
209#else /* !WORDS_BIGENDIAN */210
211#define VARATT_IS_4B(PTR) \212 ((((varattrib_1b *) (PTR))->va_header & 0x01) == 0x00)213#define VARATT_IS_4B_U(PTR) \214 ((((varattrib_1b *) (PTR))->va_header & 0x03) == 0x00)215#define VARATT_IS_4B_C(PTR) \216 ((((varattrib_1b *) (PTR))->va_header & 0x03) == 0x02)217#define VARATT_IS_1B(PTR) \218 ((((varattrib_1b *) (PTR))->va_header & 0x01) == 0x01)219#define VARATT_IS_1B_E(PTR) \220 ((((varattrib_1b *) (PTR))->va_header) == 0x01)221#define VARATT_NOT_PAD_BYTE(PTR) \222 (*((uint8 *) (PTR)) != 0)223
224/* VARSIZE_4B() should only be used on known-aligned data */225#define VARSIZE_4B(PTR) \226 ((((varattrib_4b *) (PTR))->va_4byte.va_header >> 2) & 0x3FFFFFFF)227#define VARSIZE_1B(PTR) \228 ((((varattrib_1b *) (PTR))->va_header >> 1) & 0x7F)229#define VARTAG_1B_E(PTR) \230 (((varattrib_1b_e *) (PTR))->va_tag)231
232#define SET_VARSIZE_4B(PTR,len) \233 (((varattrib_4b *) (PTR))->va_4byte.va_header = (((uint32) (len)) << 2))234#define SET_VARSIZE_4B_C(PTR,len) \235 (((varattrib_4b *) (PTR))->va_4byte.va_header = (((uint32) (len)) << 2) | 0x02)236#define SET_VARSIZE_1B(PTR,len) \237 (((varattrib_1b *) (PTR))->va_header = (((uint8) (len)) << 1) | 0x01)238#define SET_VARTAG_1B_E(PTR,tag) \239 (((varattrib_1b_e *) (PTR))->va_header = 0x01, \240 ((varattrib_1b_e *) (PTR))->va_tag = (tag))241
21 collapsed lines
242#endif /* WORDS_BIGENDIAN */243
244#define VARDATA_4B(PTR) (((varattrib_4b *) (PTR))->va_4byte.va_data)245#define VARDATA_4B_C(PTR) (((varattrib_4b *) (PTR))->va_compressed.va_data)246#define VARDATA_1B(PTR) (((varattrib_1b *) (PTR))->va_data)247#define VARDATA_1B_E(PTR) (((varattrib_1b_e *) (PTR))->va_data)248
249/*250 * Externally visible TOAST macros begin here.251 */252
253#define VARHDRSZ_EXTERNAL offsetof(varattrib_1b_e, va_data)254#define VARHDRSZ_COMPRESSED offsetof(varattrib_4b, va_compressed.va_data)255#define VARHDRSZ_SHORT offsetof(varattrib_1b, va_data)256
257#define VARATT_SHORT_MAX 0x7F258#define VARATT_CAN_MAKE_SHORT(PTR) \259 (VARATT_IS_4B_U(PTR) && \260 (VARSIZE(PTR) - VARHDRSZ + VARHDRSZ_SHORT) <= VARATT_SHORT_MAX)261#define VARATT_CONVERTED_SHORT_SIZE(PTR) \262 (VARSIZE(PTR) - VARHDRSZ + VARHDRSZ_SHORT)263
264/*265 * In consumers oblivious to data alignment, call PG_DETOAST_DATUM_PACKED(),266 * VARDATA_ANY(), VARSIZE_ANY() and VARSIZE_ANY_EXHDR(). Elsewhere, call267 * PG_DETOAST_DATUM(), VARDATA() and VARSIZE(). Directly fetching an int16,268 * int32 or wider field in the struct representing the datum layout requires269 * aligned data. memcpy() is alignment-oblivious, as are most operations on270 * datatypes, such as text, whose layout struct contains only char fields.271 *272 * Code assembling a new datum should call VARDATA() and SET_VARSIZE().273 * (Datums begin life untoasted.)274 *275 * Other macros here should usually be used only by tuple assembly/disassembly276 * code and code that specifically wants to work with still-toasted Datums.277 */278#define VARDATA(PTR) VARDATA_4B(PTR)279#define VARSIZE(PTR) VARSIZE_4B(PTR)280
281#define VARSIZE_SHORT(PTR) VARSIZE_1B(PTR)282#define VARDATA_SHORT(PTR) VARDATA_1B(PTR)283
284#define VARTAG_EXTERNAL(PTR) VARTAG_1B_E(PTR)285#define VARSIZE_EXTERNAL(PTR) (VARHDRSZ_EXTERNAL + VARTAG_SIZE(VARTAG_EXTERNAL(PTR)))286#define VARDATA_EXTERNAL(PTR) VARDATA_1B_E(PTR)287
288#define VARATT_IS_COMPRESSED(PTR) VARATT_IS_4B_C(PTR)289#define VARATT_IS_EXTERNAL(PTR) VARATT_IS_1B_E(PTR)290#define VARATT_IS_EXTERNAL_ONDISK(PTR) \291 (VARATT_IS_EXTERNAL(PTR) && VARTAG_EXTERNAL(PTR) == VARTAG_ONDISK)292#define VARATT_IS_EXTERNAL_INDIRECT(PTR) \293 (VARATT_IS_EXTERNAL(PTR) && VARTAG_EXTERNAL(PTR) == VARTAG_INDIRECT)294#define VARATT_IS_EXTERNAL_EXPANDED_RO(PTR) \295 (VARATT_IS_EXTERNAL(PTR) && VARTAG_EXTERNAL(PTR) == VARTAG_EXPANDED_RO)296#define VARATT_IS_EXTERNAL_EXPANDED_RW(PTR) \297 (VARATT_IS_EXTERNAL(PTR) && VARTAG_EXTERNAL(PTR) == VARTAG_EXPANDED_RW)298#define VARATT_IS_EXTERNAL_EXPANDED(PTR) \299 (VARATT_IS_EXTERNAL(PTR) && VARTAG_IS_EXPANDED(VARTAG_EXTERNAL(PTR)))300#define VARATT_IS_EXTERNAL_NON_EXPANDED(PTR) \301 (VARATT_IS_EXTERNAL(PTR) && !VARTAG_IS_EXPANDED(VARTAG_EXTERNAL(PTR)))302#define VARATT_IS_SHORT(PTR) VARATT_IS_1B(PTR)303#define VARATT_IS_EXTENDED(PTR) (!VARATT_IS_4B_U(PTR))304
54 collapsed lines
305#define SET_VARSIZE(PTR, len) SET_VARSIZE_4B(PTR, len)306#define SET_VARSIZE_SHORT(PTR, len) SET_VARSIZE_1B(PTR, len)307#define SET_VARSIZE_COMPRESSED(PTR, len) SET_VARSIZE_4B_C(PTR, len)308
309#define SET_VARTAG_EXTERNAL(PTR, tag) SET_VARTAG_1B_E(PTR, tag)310
311#define VARSIZE_ANY(PTR) \312 (VARATT_IS_1B_E(PTR) ? VARSIZE_EXTERNAL(PTR) : \313 (VARATT_IS_1B(PTR) ? VARSIZE_1B(PTR) : \314 VARSIZE_4B(PTR)))315
316/* Size of a varlena data, excluding header */317#define VARSIZE_ANY_EXHDR(PTR) \318 (VARATT_IS_1B_E(PTR) ? VARSIZE_EXTERNAL(PTR)-VARHDRSZ_EXTERNAL : \319 (VARATT_IS_1B(PTR) ? VARSIZE_1B(PTR)-VARHDRSZ_SHORT : \320 VARSIZE_4B(PTR)-VARHDRSZ))321
322/* caution: this will not work on an external or compressed-in-line Datum */323/* caution: this will return a possibly unaligned pointer */324#define VARDATA_ANY(PTR) \325 (VARATT_IS_1B(PTR) ? VARDATA_1B(PTR) : VARDATA_4B(PTR))326
327/* Decompressed size and compression method of a compressed-in-line Datum */328#define VARDATA_COMPRESSED_GET_EXTSIZE(PTR) \329 (((varattrib_4b *) (PTR))->va_compressed.va_tcinfo & VARLENA_EXTSIZE_MASK)330#define VARDATA_COMPRESSED_GET_COMPRESS_METHOD(PTR) \331 (((varattrib_4b *) (PTR))->va_compressed.va_tcinfo >> VARLENA_EXTSIZE_BITS)332
333/* Same for external Datums; but note argument is a struct varatt_external */334#define VARATT_EXTERNAL_GET_EXTSIZE(toast_pointer) \335 ((toast_pointer).va_extinfo & VARLENA_EXTSIZE_MASK)336#define VARATT_EXTERNAL_GET_COMPRESS_METHOD(toast_pointer) \337 ((toast_pointer).va_extinfo >> VARLENA_EXTSIZE_BITS)338
339#define VARATT_EXTERNAL_SET_SIZE_AND_COMPRESS_METHOD(toast_pointer, len, cm) \340 do { \341 Assert((cm) == TOAST_PGLZ_COMPRESSION_ID || \342 (cm) == TOAST_LZ4_COMPRESSION_ID); \343 ((toast_pointer).va_extinfo = \344 (len) | ((uint32) (cm) << VARLENA_EXTSIZE_BITS)); \345 } while (0)346
347/*348 * Testing whether an externally-stored value is compressed now requires349 * comparing size stored in va_extinfo (the actual length of the external data)350 * to rawsize (the original uncompressed datum's size). The latter includes351 * VARHDRSZ overhead, the former doesn't. We never use compression unless it352 * actually saves space, so we expect either equality or less-than.353 */354#define VARATT_EXTERNAL_IS_COMPRESSED(toast_pointer) \355 (VARATT_EXTERNAL_GET_EXTSIZE(toast_pointer) < \356 (toast_pointer).va_rawsize - VARHDRSZ)357
358#endifThere’s quite a lot going on here, especially if you’re not too familiar with C, so let’s break it down a bit.
First, let’s take a look at the different structs we’ve got here. There are essentially 4 different possible structures that the varlena can have:
1. varattrib_4b.va_4byte
This is the normal 4-byte header that’s used when the value is not long enough to be compressed or out-of-lined. The header itself contains the length of the data within the 4-byte header, but as we’ll see in varattrib_4b.va_compressed and varattrib_1b, the first bit of the varlena header is used to hold a flag indicating whether the data uses the varattrib_1b or varattrib_1b_e formats and the second bit is used to hold a flag indicating whether the data is compressed, so the actual length is stored in the other 30 bits.
This means that the maximum length we can have is which is probably big enough given the default page size is 8,192 bytes.
2. varattrib_4b.va_compressed
This is an 8-byte header used when the value is big enough to need compressing, but not big enough to need out-of-lining. This struct is the same as the 4-byte header but adds an extra uint32 to store information about the compression.
Note: for people unfamiliar with union in C, this is basically saying that the struct varattrib_4b can refer to either the struct va_4byte or va_compressed within the same bit of memory. It’s not immediately clear to me why these two structs are in a union but the other two aren’t. Based on the comment above these structs, I presume it’s because the varattrib_4b union members are aligned as they consist of uint32 fields, whereas the varattrib_1b and varattrib_1b_e structs are not aligned because they have one or two uint8 fields inside them. I’m not entirely certain on this, though, so if any C experts want to chime in, feel free.
Also, while we’re at it, it seems silly that va_compressed is part of varattrib_4b when the header is 8 bytes long, not 4 bytes as the name implies, but I guess I’ve never written a database used by millions so I can’t really criticise.
3. varattrib_1b
This is referred to as a “short-header” varlena. It’s essentially the same as the va_4byte variant but it is packed into a single byte instead of 4 bytes.
The first bit is used to indicate whether it is external or not while the other 7 bits contain the length of the data. This means that the varattrib_1b non-external struct can only be used to store values less than 0x7f = 127 bytes in length.
For an example of this, we can look at the bytes for the title of the poem “Ozymandias”, which looks like 17 4f 7a 79 6d 61 6e 64 69 61 73 = \x17 O z y m a n d i a s. In this case, the header is 0x17 but remember that the first bit is used for the “external” flag, so we need to shift it down one bit to get the actual size value: 0x17 << 1 = 0xb = 11. The title of the poem, “Ozymandias”, is 10 characters long so the length here is 11 including the 1-byte header itself.
4. varattrib_1b_e
This extends the varattrib_1b struct to add an additional byte, called the vartag, to indicate what type of TOASTed data we are looking at. You can tell whether a varlena uses varattrib_1b or varattrib_1b_e by checking whether the first byte is exactly equal to 0x01, meaning the “length” part of the first byte is zero. This would be 0x80 on big-endian systems and 0x01 on little-endian systems.
The enum for this data type, called vartag_external, has 4 options:
- indirect,
- expanded (read-only),
- expanded (read-write) and
- on-disk.
We’re talking about the “on-disk” variant while the other types of external TOAST data refer to where the TOAST pointer refers to a value in the memory of the server process. For more details on indirect and expanded, check out PostgreSQL Documentation: 73.2.2. Out-of-Line, In-Memory TOAST Storage.
To help visualise these, here’s a handy flow diagram:
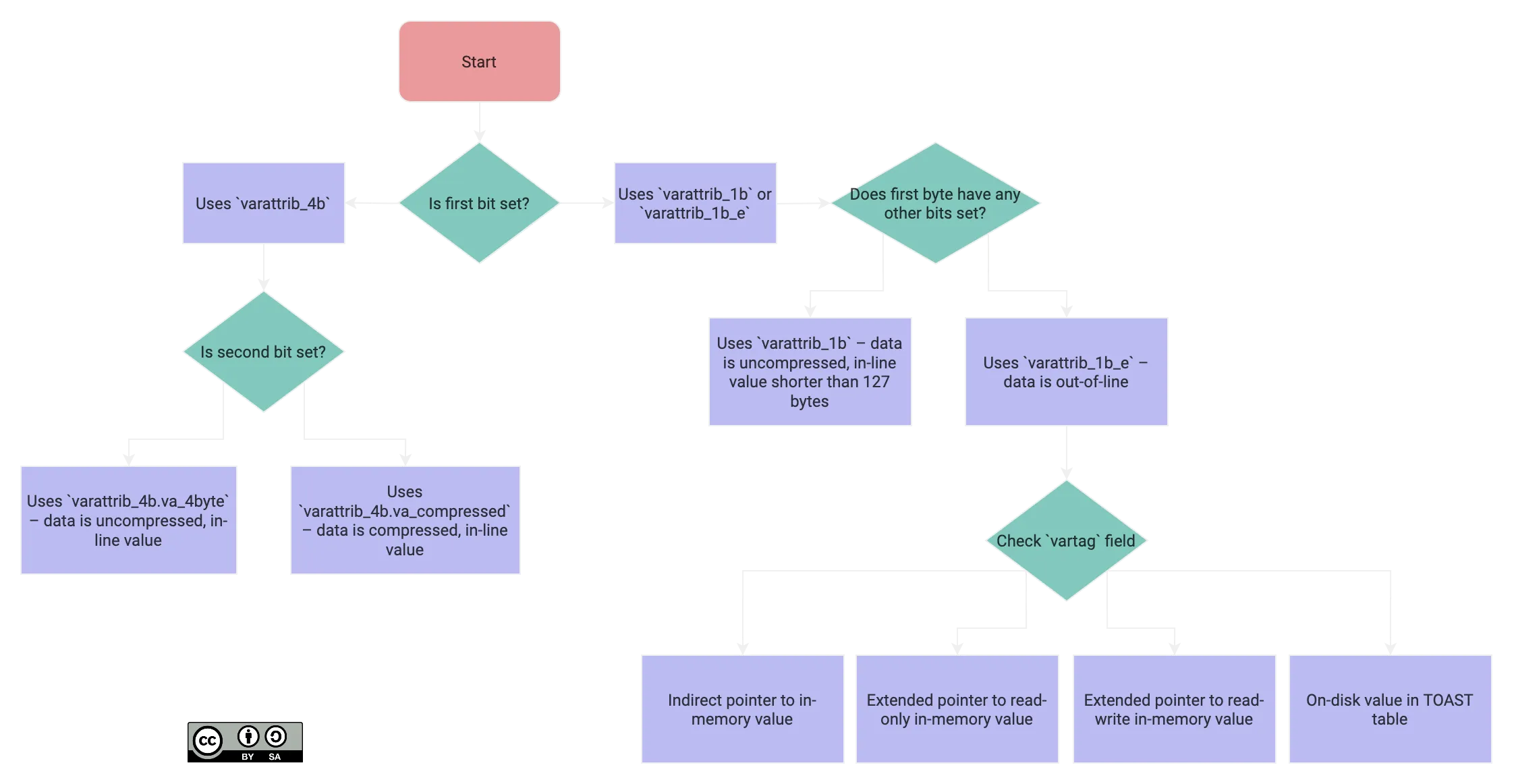
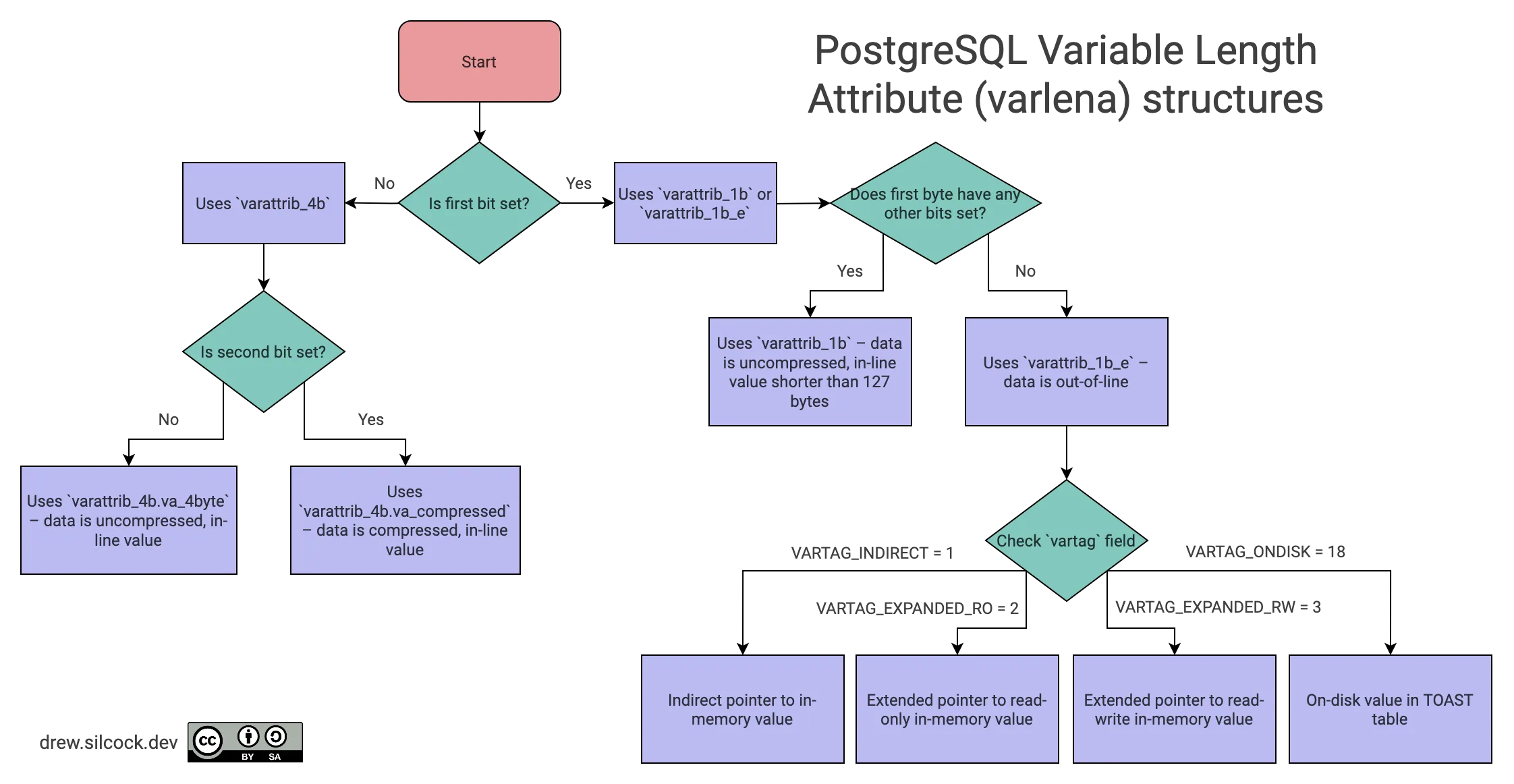
Looking back at our poem varlena headers
Now that we understand what structs the variable length attributes can correspond to, we can reinterpret the headers for our poems:
“Ozymandias” header – 04 0a 00 00
First things first, we can see that the first byte is 0x04 = 0b00000100 so neither of the first two bits are set. This means that the value is in-line and uncompressed which means we’re looking at the varattrib_4b.va_4byte struct.
We can then get the length of the poem in bytes by doing (header >> 2) - header size = (0x0a04 >> 2) - 4 = 0x281 - 4 = 641 - 4 = 637.
If you’ve got a good memory and eye for numbers, you might be thinking “why is this giving 637 when the length earlier gave 631”? The answer is that length() does not give you the size of the string in bytes but the length of the string in characters. In our poem we have three non-ASCII characters – U+2014 — (UTF-8 e2 80 94), U+201C “ (UTF-8 value e2 80 9c) and U+201D ” (UTF-8 value e2 80 9d) which count as 3 characters but total 9 bytes, making up the 6 byte difference.
”Ode on a Grecian Urn” header - f2 1a 00 00 8c 09 00 00
Let’s look at the first byte again: 0xf2 = 0b11110010. This has the first bit unset meaning it is not using the 1b format but the second bit is set, meaning the value is compressed. Taking (0x1af2 >> 2) - 8 = 0x6B4 = 1716 gives the size in bytes.
The second 4-byte value 0x098c gives us the decompressed size and compression method. The first 30 bits are used for the uncompressed size while the last 2 bits are used for the compression method. To get the uncompressed size, we need to bitwise-and 0x098c with a the bitmask (1 << 30) - 1, i.e. a 32-bit number with 1 in the first 30 places and 0 in the last 2 places: 0x098c & ((1 << 30) - 1) = 0x098c & 0x3fffffff = 0x98c so the uncompressed size is 2,444 bytes. The poem is 2,442 characters long so that makes sense – there’s probably an em dash in there somewhere5.
There is also a single null byte before the actual poem starts. I’m not exactly sure what this is but I presume it’s an artifact of the compression method being used.
”The Waste Land” header - 01 12
This one has a short header. The first byte is simply 0x01 which tells you that this is an external value. Looking at the next byte, the vartag, you see 0x12 = 18 which tells you that this is an external on-disk TOAST pointer.
We’ve made great progress in understanding how Postgres stores variable length attributes, but we still haven’t tracked down the actual TOASTed values from the main-table tuple data. So what’s the next step?
Following the white rabbit
Let’s look at the whole 18 bytes for the content column value in the main table data for “The Waste Land”:
1┌────────┬─────────────────────────┬─────────────────────────┬────────┬────────┐2│00000000│ 01 12 ed 4e 00 00 24 2d ┊ 00 00 ff 66 00 00 d5 61 │••×N⋄⋄$-┊⋄⋄×f⋄⋄×a│3│00000010│ 00 00 ┊ │⋄⋄ ┊ │4└────────┴─────────────────────────┴─────────────────────────┴────────┴────────┘We understand the first 2 bytes now, but there’s still 16 bytes left that we haven’t explained.
Looking back at the detoast_attr() function, we can see that the function calls attr = toast_fetch_datum(attr) to retrieve the data from the external store. The answer must be in there somewhere.
333 collapsed lines
1/*-------------------------------------------------------------------------2 *3 * detoast.c4 * Retrieve compressed or external variable size attributes.5 *6 * Copyright (c) 2000-2024, PostgreSQL Global Development Group7 *8 * IDENTIFICATION9 * src/backend/access/common/detoast.c10 *11 *-------------------------------------------------------------------------12 */13
14#include "postgres.h"15
16#include "access/detoast.h"17#include "access/table.h"18#include "access/tableam.h"19#include "access/toast_internals.h"20#include "common/int.h"21#include "common/pg_lzcompress.h"22#include "utils/expandeddatum.h"23#include "utils/rel.h"24
25static struct varlena *toast_fetch_datum(struct varlena *attr);26static struct varlena *toast_fetch_datum_slice(struct varlena *attr,27 int32 sliceoffset,28 int32 slicelength);29static struct varlena *toast_decompress_datum(struct varlena *attr);30static struct varlena *toast_decompress_datum_slice(struct varlena *attr, int32 slicelength);31
32/* ----------33 * detoast_external_attr -34 *35 * Public entry point to get back a toasted value from36 * external source (possibly still in compressed format).37 *38 * This will return a datum that contains all the data internally, ie, not39 * relying on external storage or memory, but it can still be compressed or40 * have a short header. Note some callers assume that if the input is an41 * EXTERNAL datum, the result will be a pfree'able chunk.42 * ----------43 */44struct varlena *45detoast_external_attr(struct varlena *attr)46{47 struct varlena *result;48
49 if (VARATT_IS_EXTERNAL_ONDISK(attr))50 {51 /*52 * This is an external stored plain value53 */54 result = toast_fetch_datum(attr);55 }56 else if (VARATT_IS_EXTERNAL_INDIRECT(attr))57 {58 /*59 * This is an indirect pointer --- dereference it60 */61 struct varatt_indirect redirect;62
63 VARATT_EXTERNAL_GET_POINTER(redirect, attr);64 attr = (struct varlena *) redirect.pointer;65
66 /* nested indirect Datums aren't allowed */67 Assert(!VARATT_IS_EXTERNAL_INDIRECT(attr));68
69 /* recurse if value is still external in some other way */70 if (VARATT_IS_EXTERNAL(attr))71 return detoast_external_attr(attr);72
73 /*74 * Copy into the caller's memory context, in case caller tries to75 * pfree the result.76 */77 result = (struct varlena *) palloc(VARSIZE_ANY(attr));78 memcpy(result, attr, VARSIZE_ANY(attr));79 }80 else if (VARATT_IS_EXTERNAL_EXPANDED(attr))81 {82 /*83 * This is an expanded-object pointer --- get flat format84 */85 ExpandedObjectHeader *eoh;86 Size resultsize;87
88 eoh = DatumGetEOHP(PointerGetDatum(attr));89 resultsize = EOH_get_flat_size(eoh);90 result = (struct varlena *) palloc(resultsize);91 EOH_flatten_into(eoh, (void *) result, resultsize);92 }93 else94 {95 /*96 * This is a plain value inside of the main tuple - why am I called?97 */98 result = attr;99 }100
101 return result;102}103
104
105/* ----------106 * detoast_attr -107 *108 * Public entry point to get back a toasted value from compression109 * or external storage. The result is always non-extended varlena form.110 *111 * Note some callers assume that if the input is an EXTERNAL or COMPRESSED112 * datum, the result will be a pfree'able chunk.113 * ----------114 */115struct varlena *116detoast_attr(struct varlena *attr)117{118 if (VARATT_IS_EXTERNAL_ONDISK(attr))119 {120 /*121 * This is an externally stored datum --- fetch it back from there122 */123 attr = toast_fetch_datum(attr);124 /* If it's compressed, decompress it */125 if (VARATT_IS_COMPRESSED(attr))126 {127 struct varlena *tmp = attr;128
129 attr = toast_decompress_datum(tmp);130 pfree(tmp);131 }132 }133 else if (VARATT_IS_EXTERNAL_INDIRECT(attr))134 {135 /*136 * This is an indirect pointer --- dereference it137 */138 struct varatt_indirect redirect;139
140 VARATT_EXTERNAL_GET_POINTER(redirect, attr);141 attr = (struct varlena *) redirect.pointer;142
143 /* nested indirect Datums aren't allowed */144 Assert(!VARATT_IS_EXTERNAL_INDIRECT(attr));145
146 /* recurse in case value is still extended in some other way */147 attr = detoast_attr(attr);148
149 /* if it isn't, we'd better copy it */150 if (attr == (struct varlena *) redirect.pointer)151 {152 struct varlena *result;153
154 result = (struct varlena *) palloc(VARSIZE_ANY(attr));155 memcpy(result, attr, VARSIZE_ANY(attr));156 attr = result;157 }158 }159 else if (VARATT_IS_EXTERNAL_EXPANDED(attr))160 {161 /*162 * This is an expanded-object pointer --- get flat format163 */164 attr = detoast_external_attr(attr);165 /* flatteners are not allowed to produce compressed/short output */166 Assert(!VARATT_IS_EXTENDED(attr));167 }168 else if (VARATT_IS_COMPRESSED(attr))169 {170 /*171 * This is a compressed value inside of the main tuple172 */173 attr = toast_decompress_datum(attr);174 }175 else if (VARATT_IS_SHORT(attr))176 {177 /*178 * This is a short-header varlena --- convert to 4-byte header format179 */180 Size data_size = VARSIZE_SHORT(attr) - VARHDRSZ_SHORT;181 Size new_size = data_size + VARHDRSZ;182 struct varlena *new_attr;183
184 new_attr = (struct varlena *) palloc(new_size);185 SET_VARSIZE(new_attr, new_size);186 memcpy(VARDATA(new_attr), VARDATA_SHORT(attr), data_size);187 attr = new_attr;188 }189
190 return attr;191}192
193
194/* ----------195 * detoast_attr_slice -196 *197 * Public entry point to get back part of a toasted value198 * from compression or external storage.199 *200 * sliceoffset is where to start (zero or more)201 * If slicelength < 0, return everything beyond sliceoffset202 * ----------203 */204struct varlena *205detoast_attr_slice(struct varlena *attr,206 int32 sliceoffset, int32 slicelength)207{208 struct varlena *preslice;209 struct varlena *result;210 char *attrdata;211 int32 slicelimit;212 int32 attrsize;213
214 if (sliceoffset < 0)215 elog(ERROR, "invalid sliceoffset: %d", sliceoffset);216
217 /*218 * Compute slicelimit = offset + length, or -1 if we must fetch all of the219 * value. In case of integer overflow, we must fetch all.220 */221 if (slicelength < 0)222 slicelimit = -1;223 else if (pg_add_s32_overflow(sliceoffset, slicelength, &slicelimit))224 slicelength = slicelimit = -1;225
226 if (VARATT_IS_EXTERNAL_ONDISK(attr))227 {228 struct varatt_external toast_pointer;229
230 VARATT_EXTERNAL_GET_POINTER(toast_pointer, attr);231
232 /* fast path for non-compressed external datums */233 if (!VARATT_EXTERNAL_IS_COMPRESSED(toast_pointer))234 return toast_fetch_datum_slice(attr, sliceoffset, slicelength);235
236 /*237 * For compressed values, we need to fetch enough slices to decompress238 * at least the requested part (when a prefix is requested).239 * Otherwise, just fetch all slices.240 */241 if (slicelimit >= 0)242 {243 int32 max_size = VARATT_EXTERNAL_GET_EXTSIZE(toast_pointer);244
245 /*246 * Determine maximum amount of compressed data needed for a prefix247 * of a given length (after decompression).248 *249 * At least for now, if it's LZ4 data, we'll have to fetch the250 * whole thing, because there doesn't seem to be an API call to251 * determine how much compressed data we need to be sure of being252 * able to decompress the required slice.253 */254 if (VARATT_EXTERNAL_GET_COMPRESS_METHOD(toast_pointer) ==255 TOAST_PGLZ_COMPRESSION_ID)256 max_size = pglz_maximum_compressed_size(slicelimit, max_size);257
258 /*259 * Fetch enough compressed slices (compressed marker will get set260 * automatically).261 */262 preslice = toast_fetch_datum_slice(attr, 0, max_size);263 }264 else265 preslice = toast_fetch_datum(attr);266 }267 else if (VARATT_IS_EXTERNAL_INDIRECT(attr))268 {269 struct varatt_indirect redirect;270
271 VARATT_EXTERNAL_GET_POINTER(redirect, attr);272
273 /* nested indirect Datums aren't allowed */274 Assert(!VARATT_IS_EXTERNAL_INDIRECT(redirect.pointer));275
276 return detoast_attr_slice(redirect.pointer,277 sliceoffset, slicelength);278 }279 else if (VARATT_IS_EXTERNAL_EXPANDED(attr))280 {281 /* pass it off to detoast_external_attr to flatten */282 preslice = detoast_external_attr(attr);283 }284 else285 preslice = attr;286
287 Assert(!VARATT_IS_EXTERNAL(preslice));288
289 if (VARATT_IS_COMPRESSED(preslice))290 {291 struct varlena *tmp = preslice;292
293 /* Decompress enough to encompass the slice and the offset */294 if (slicelimit >= 0)295 preslice = toast_decompress_datum_slice(tmp, slicelimit);296 else297 preslice = toast_decompress_datum(tmp);298
299 if (tmp != attr)300 pfree(tmp);301 }302
303 if (VARATT_IS_SHORT(preslice))304 {305 attrdata = VARDATA_SHORT(preslice);306 attrsize = VARSIZE_SHORT(preslice) - VARHDRSZ_SHORT;307 }308 else309 {310 attrdata = VARDATA(preslice);311 attrsize = VARSIZE(preslice) - VARHDRSZ;312 }313
314 /* slicing of datum for compressed cases and plain value */315
316 if (sliceoffset >= attrsize)317 {318 sliceoffset = 0;319 slicelength = 0;320 }321 else if (slicelength < 0 || slicelimit > attrsize)322 slicelength = attrsize - sliceoffset;323
324 result = (struct varlena *) palloc(slicelength + VARHDRSZ);325 SET_VARSIZE(result, slicelength + VARHDRSZ);326
327 memcpy(VARDATA(result), attrdata + sliceoffset, slicelength);328
329 if (preslice != attr)330 pfree(preslice);331
332 return result;333}334
335/* ----------336 * toast_fetch_datum -337 *338 * Reconstruct an in memory Datum from the chunks saved339 * in the toast relation340 * ----------341 */342static struct varlena *343toast_fetch_datum(struct varlena *attr)344{345 Relation toastrel;346 struct varlena *result;347 struct varatt_external toast_pointer;348 int32 attrsize;349
350 if (!VARATT_IS_EXTERNAL_ONDISK(attr))351 elog(ERROR, "toast_fetch_datum shouldn't be called for non-ondisk datums");352
353 /* Must copy to access aligned fields */354 VARATT_EXTERNAL_GET_POINTER(toast_pointer, attr);355
356 attrsize = VARATT_EXTERNAL_GET_EXTSIZE(toast_pointer);357
358 result = (struct varlena *) palloc(attrsize + VARHDRSZ);359
360 if (VARATT_EXTERNAL_IS_COMPRESSED(toast_pointer))361 SET_VARSIZE_COMPRESSED(result, attrsize + VARHDRSZ);362 else363 SET_VARSIZE(result, attrsize + VARHDRSZ);364
365 if (attrsize == 0)366 return result; /* Probably shouldn't happen, but just in367 * case. */368
369 /*370 * Open the toast relation and its indexes371 */372 toastrel = table_open(toast_pointer.va_toastrelid, AccessShareLock);373
374 /* Fetch all chunks */375 table_relation_fetch_toast_slice(toastrel, toast_pointer.va_valueid,376 attrsize, 0, attrsize, result);377
378 /* Close toast table */379 table_close(toastrel, AccessShareLock);380
381 return result;382}383
263 collapsed lines
384/* ----------385 * toast_fetch_datum_slice -386 *387 * Reconstruct a segment of a Datum from the chunks saved388 * in the toast relation389 *390 * Note that this function supports non-compressed external datums391 * and compressed external datums (in which case the requested slice392 * has to be a prefix, i.e. sliceoffset has to be 0).393 * ----------394 */395static struct varlena *396toast_fetch_datum_slice(struct varlena *attr, int32 sliceoffset,397 int32 slicelength)398{399 Relation toastrel;400 struct varlena *result;401 struct varatt_external toast_pointer;402 int32 attrsize;403
404 if (!VARATT_IS_EXTERNAL_ONDISK(attr))405 elog(ERROR, "toast_fetch_datum_slice shouldn't be called for non-ondisk datums");406
407 /* Must copy to access aligned fields */408 VARATT_EXTERNAL_GET_POINTER(toast_pointer, attr);409
410 /*411 * It's nonsense to fetch slices of a compressed datum unless when it's a412 * prefix -- this isn't lo_* we can't return a compressed datum which is413 * meaningful to toast later.414 */415 Assert(!VARATT_EXTERNAL_IS_COMPRESSED(toast_pointer) || 0 == sliceoffset);416
417 attrsize = VARATT_EXTERNAL_GET_EXTSIZE(toast_pointer);418
419 if (sliceoffset >= attrsize)420 {421 sliceoffset = 0;422 slicelength = 0;423 }424
425 /*426 * When fetching a prefix of a compressed external datum, account for the427 * space required by va_tcinfo, which is stored at the beginning as an428 * int32 value.429 */430 if (VARATT_EXTERNAL_IS_COMPRESSED(toast_pointer) && slicelength > 0)431 slicelength = slicelength + sizeof(int32);432
433 /*434 * Adjust length request if needed. (Note: our sole caller,435 * detoast_attr_slice, protects us against sliceoffset + slicelength436 * overflowing.)437 */438 if (((sliceoffset + slicelength) > attrsize) || slicelength < 0)439 slicelength = attrsize - sliceoffset;440
441 result = (struct varlena *) palloc(slicelength + VARHDRSZ);442
443 if (VARATT_EXTERNAL_IS_COMPRESSED(toast_pointer))444 SET_VARSIZE_COMPRESSED(result, slicelength + VARHDRSZ);445 else446 SET_VARSIZE(result, slicelength + VARHDRSZ);447
448 if (slicelength == 0)449 return result; /* Can save a lot of work at this point! */450
451 /* Open the toast relation */452 toastrel = table_open(toast_pointer.va_toastrelid, AccessShareLock);453
454 /* Fetch all chunks */455 table_relation_fetch_toast_slice(toastrel, toast_pointer.va_valueid,456 attrsize, sliceoffset, slicelength,457 result);458
459 /* Close toast table */460 table_close(toastrel, AccessShareLock);461
462 return result;463}464
465/* ----------466 * toast_decompress_datum -467 *468 * Decompress a compressed version of a varlena datum469 */470static struct varlena *471toast_decompress_datum(struct varlena *attr)472{473 ToastCompressionId cmid;474
475 Assert(VARATT_IS_COMPRESSED(attr));476
477 /*478 * Fetch the compression method id stored in the compression header and479 * decompress the data using the appropriate decompression routine.480 */481 cmid = TOAST_COMPRESS_METHOD(attr);482 switch (cmid)483 {484 case TOAST_PGLZ_COMPRESSION_ID:485 return pglz_decompress_datum(attr);486 case TOAST_LZ4_COMPRESSION_ID:487 return lz4_decompress_datum(attr);488 default:489 elog(ERROR, "invalid compression method id %d", cmid);490 return NULL; /* keep compiler quiet */491 }492}493
494
495/* ----------496 * toast_decompress_datum_slice -497 *498 * Decompress the front of a compressed version of a varlena datum.499 * offset handling happens in detoast_attr_slice.500 * Here we just decompress a slice from the front.501 */502static struct varlena *503toast_decompress_datum_slice(struct varlena *attr, int32 slicelength)504{505 ToastCompressionId cmid;506
507 Assert(VARATT_IS_COMPRESSED(attr));508
509 /*510 * Some callers may pass a slicelength that's more than the actual511 * decompressed size. If so, just decompress normally. This avoids512 * possibly allocating a larger-than-necessary result object, and may be513 * faster and/or more robust as well. Notably, some versions of liblz4514 * have been seen to give wrong results if passed an output size that is515 * more than the data's true decompressed size.516 */517 if ((uint32) slicelength >= TOAST_COMPRESS_EXTSIZE(attr))518 return toast_decompress_datum(attr);519
520 /*521 * Fetch the compression method id stored in the compression header and522 * decompress the data slice using the appropriate decompression routine.523 */524 cmid = TOAST_COMPRESS_METHOD(attr);525 switch (cmid)526 {527 case TOAST_PGLZ_COMPRESSION_ID:528 return pglz_decompress_datum_slice(attr, slicelength);529 case TOAST_LZ4_COMPRESSION_ID:530 return lz4_decompress_datum_slice(attr, slicelength);531 default:532 elog(ERROR, "invalid compression method id %d", cmid);533 return NULL; /* keep compiler quiet */534 }535}536
537/* ----------538 * toast_raw_datum_size -539 *540 * Return the raw (detoasted) size of a varlena datum541 * (including the VARHDRSZ header)542 * ----------543 */544Size545toast_raw_datum_size(Datum value)546{547 struct varlena *attr = (struct varlena *) DatumGetPointer(value);548 Size result;549
550 if (VARATT_IS_EXTERNAL_ONDISK(attr))551 {552 /* va_rawsize is the size of the original datum -- including header */553 struct varatt_external toast_pointer;554
555 VARATT_EXTERNAL_GET_POINTER(toast_pointer, attr);556 result = toast_pointer.va_rawsize;557 }558 else if (VARATT_IS_EXTERNAL_INDIRECT(attr))559 {560 struct varatt_indirect toast_pointer;561
562 VARATT_EXTERNAL_GET_POINTER(toast_pointer, attr);563
564 /* nested indirect Datums aren't allowed */565 Assert(!VARATT_IS_EXTERNAL_INDIRECT(toast_pointer.pointer));566
567 return toast_raw_datum_size(PointerGetDatum(toast_pointer.pointer));568 }569 else if (VARATT_IS_EXTERNAL_EXPANDED(attr))570 {571 result = EOH_get_flat_size(DatumGetEOHP(value));572 }573 else if (VARATT_IS_COMPRESSED(attr))574 {575 /* here, va_rawsize is just the payload size */576 result = VARDATA_COMPRESSED_GET_EXTSIZE(attr) + VARHDRSZ;577 }578 else if (VARATT_IS_SHORT(attr))579 {580 /*581 * we have to normalize the header length to VARHDRSZ or else the582 * callers of this function will be confused.583 */584 result = VARSIZE_SHORT(attr) - VARHDRSZ_SHORT + VARHDRSZ;585 }586 else587 {588 /* plain untoasted datum */589 result = VARSIZE(attr);590 }591 return result;592}593
594/* ----------595 * toast_datum_size596 *597 * Return the physical storage size (possibly compressed) of a varlena datum598 * ----------599 */600Size601toast_datum_size(Datum value)602{603 struct varlena *attr = (struct varlena *) DatumGetPointer(value);604 Size result;605
606 if (VARATT_IS_EXTERNAL_ONDISK(attr))607 {608 /*609 * Attribute is stored externally - return the extsize whether610 * compressed or not. We do not count the size of the toast pointer611 * ... should we?612 */613 struct varatt_external toast_pointer;614
615 VARATT_EXTERNAL_GET_POINTER(toast_pointer, attr);616 result = VARATT_EXTERNAL_GET_EXTSIZE(toast_pointer);617 }618 else if (VARATT_IS_EXTERNAL_INDIRECT(attr))619 {620 struct varatt_indirect toast_pointer;621
622 VARATT_EXTERNAL_GET_POINTER(toast_pointer, attr);623
624 /* nested indirect Datums aren't allowed */625 Assert(!VARATT_IS_EXTERNAL_INDIRECT(attr));626
627 return toast_datum_size(PointerGetDatum(toast_pointer.pointer));628 }629 else if (VARATT_IS_EXTERNAL_EXPANDED(attr))630 {631 result = EOH_get_flat_size(DatumGetEOHP(value));632 }633 else if (VARATT_IS_SHORT(attr))634 {635 result = VARSIZE_SHORT(attr);636 }637 else638 {639 /*640 * Attribute is stored inline either compressed or not, just calculate641 * the size of the datum in either case.642 */643 result = VARSIZE(attr);644 }645 return result;646}Here we see how Postgres is linking the main table data back to the external TOAST table. It’s casting the 16 bytes to the struct varatt_external() and using the fields varatt_external.va_toastrelid and varatt_external.va_valueid to pull in the values from the TOAST table.
We’ve already seen this struct, in fact – it’s in the src/include/varatt.h file we saw earlier. It’s got 4 fields in total, each one 4 bytes long:
30...31
32typedef struct varatt_external33{34 int32 va_rawsize; /* Original data size (includes header) */35 uint32 va_extinfo; /* External saved size (without header) and36 * compression method */37 Oid va_valueid; /* Unique ID of value within TOAST table */38 Oid va_toastrelid; /* RelID of TOAST table containing it */39}40
41...Each of these 4 struct fields is 4 bytes each, making up the 16 bytes left. The va_rawsize and va_extinfo aren’t particularly interesting for us at the moment but the final last fields give us what we need. We can see that the ID of the value within the toast table, va_valueid, is ff 66 00 00 = 26367 while the toast relation ID, va_toastrelid, is d5 61 00 00 = 25045 – this matches the OID of the pg_toast_25042 we saw earlier6.
We can follow the va_valueid through to the TOAST table like so7:
1blogdb=# select ctid, chunk_id, chunk_seq2blogdb-# from pg_toast.pg_toast_250423blogdb-# where chunk_id = 26367;4 ctid | chunk_id | chunk_seq5-------+----------+-----------6 (0,1) | 26367 | 07 (0,2) | 26367 | 18 (0,3) | 26367 | 29 (0,4) | 26367 | 310 (1,1) | 26367 | 411 (1,2) | 26367 | 512(6 rows)So then we can see that all the detoast_attr() function is doing is pulling these chunks together in order according to the chunk_seq values to get the full poem back out. Let’s write a quick helper to look at this data:
1function print-toast-data {2 run-and-decode "select chunk_data from pg_toast.pg_toast_25042 where chunk_id = $1 and chunk_seq = $2"3}We can run through the 6 chunks to see the bits and pieces of the poem, still compressed but recognisable:
1$ print-toast-data 26367 0 | head -n 202┌────────┬─────────────────────────┬─────────────────────────┬────────┬────────┐3│00000000│ e9 4e 00 00 00 20 20 e2 ┊ 80 9c 4e 61 6d 00 20 53 │×N⋄⋄⋄ ×┊××Nam⋄ S│4│00000010│ 69 62 79 6c 6c 61 00 6d ┊ 20 71 75 69 64 65 6d 00 │ibylla⋄m┊ quidem⋄│5│00000020│ 20 43 75 6d 69 73 20 65 ┊ 00 67 6f 20 69 70 73 65 │ Cumis e┊⋄go ipse│6│00000030│ 20 00 6f 63 75 6c 69 73 ┊ 20 6d 00 65 69 73 0a 20 │ ⋄oculis┊ m⋄eis_ │7│00000040│ 20 76 69 00 64 69 20 69 ┊ 6e 20 61 6d 00 70 75 6c │ vi⋄di i┊n am⋄pul│8│00000050│ 6c 61 20 70 65 00 6e 64 ┊ 65 72 65 2c 20 65 00 74 │la pe⋄nd┊ere, e⋄t│9│00000060│ 20 63 75 6d 20 69 6c 00 ┊ 6c 69 20 70 75 65 72 69 │ cum il⋄┊li pueri│10│00000070│ 00 20 64 69 63 65 72 65 ┊ 6e 00 74 3a 0a 20 20 ce │⋄ dicere┊n⋄t:_ ×│11│00000080│ a3 e1 00 bd b7 ce b2 cf ┊ 85 ce bb 00 ce bb ce b1 │××⋄×××××┊×××⋄××××│12│00000090│ 20 cf 84 e1 00 bd b7 20 ┊ ce b8 e1 bd b3 00 ce bb │ ×××⋄×× ┊×××××⋄××│13│000000a0│ ce b5 ce b9 cf 82 00 3b ┊ 20 72 65 73 70 6f 6e 20 │××××××⋄;┊ respon │14│000000b0│ 64 65 62 61 74 01 48 61 ┊ 3a 00 20 e1 bc 80 cf 80 │debat•Ha┊:⋄ ×××××│15│000000c0│ ce bf 00 ce b8 ce b1 ce ┊ bd ce b5 20 e1 bf 96 ce │××⋄×××××┊××× ××××│16│000000d0│ bd 05 36 cf 89 80 2e e2 ┊ 80 9d 0a 0a 20 05 01 00 │ו6×××.×┊××__ ••⋄│17│000000e0│ 5f 46 6f 72 20 45 7a 72 ┊ 80 61 20 50 6f 75 6e 64 │_For Ezr┊×a Pound│18│000000f0│ 07 19 00 69 6c 20 6d 69 ┊ 67 6c 69 00 6f 72 20 66 │••⋄il mi┊gli⋄or f│19│00000100│ 61 62 62 72 18 6f 5f 0a ┊ 01 01 03 1d 49 2e 20 00 │abbr•o__┊••••I. ⋄│20│00000110│ 54 48 45 20 42 55 52 49 ┊ 20 41 4c 20 4f 46 02 0e │THE BURI┊ AL OF••│21│00000120│ 44 45 04 41 44 02 22 41 ┊ 70 72 69 6c 00 20 69 73 │DE•AD•"A┊pril⋄ is│22
23$ print-toast-data 26367 5 | head -n 2024┌────────┬─────────────────────────┬─────────────────────────┬────────┬────────┐25│00000000│ 10 68 6f 72 64 31 c8 77 ┊ 61 72 06 6d a4 71 21 47 │•hord1×w┊ar•m×q!G│26│00000010│ 65 6e 64 6c 65 04 73 73 ┊ 71 5a 69 6e 73 2c 20 cc │endle•ss┊qZins, ×│27│00000020│ 73 74 a1 fb 62 df 6e 20 ┊ 35 d2 c1 3a 85 81 f1 52 │st××b×n ┊5××:×××R│28│00000030│ b1 3f 64 20 62 79 c4 93 ┊ 84 61 74 01 57 69 7a 6f │×?d by××┊×at•Wizo│29│00000040│ 6e 13 ce 9d 0f 01 16 33 ┊ f2 d0 07 ed 31 07 74 79 │n•×ו••3┊×ו×1•ty│30│00000050│ 23 d8 cd 4d 8e 43 01 84 ┊ d3 70 72 65 e1 ae 03 0c │#××M×C•×┊×pre×ו_│31│00000060│ 20 62 75 72 73 74 26 df ┊ 76 69 8c 6f 6c 61 00 12 │ burst&×┊vi×ola⋄•│32│00000070│ 20 46 61 6c 02 c1 01 e6 ┊ 21 4a 65 72 75 73 61 6c │ Fal•×•×┊!Jerusal│33│00000080│ 10 65 6d 20 41 b1 96 73 ┊ 20 41 80 6c 65 78 61 6e │•em A××s┊ A×lexan│34│00000090│ 64 72 f2 9f 00 56 69 65 ┊ 6e 6e 61 20 4c 08 6f 6e │dr××⋄Vie┊nna L•on│35│000000a0│ 64 12 3e 55 6e 72 65 0c ┊ 61 6c 82 dc 13 c8 20 64 │d•>Unre_┊al××•× d│36│000000b0│ 72 65 12 77 31 5d 20 6c ┊ 31 ed 62 6c 61 80 63 6b │re•w1] l┊1×bla×ck│37│000000c0│ 20 68 61 69 72 b1 9b 0c ┊ 20 74 81 f2 34 c0 66 69 │ hair××_┊ t××4×fi│38│000000d0│ 64 64 03 e1 fe a4 65 20 ┊ 6d 75 73 69 63 73 13 f2 │dd•×××e ┊musics•×│39│000000e0│ 11 8a 73 74 41 3d 82 e1 ┊ 01 c2 61 c4 74 73 c3 ac │•×stA=××┊•×a×ts××│40│000000f0│ 62 61 62 94 26 0c d0 83 ┊ 92 4e 73 75 73 74 6c 65 │bab×&_××┊×Nsustle│41│00000100│ 64 b3 46 c2 62 61 fb 74 ┊ 68 65 69 51 e8 31 e4 49 │d×F×ba×t┊heiQ×1×I│42│00000110│ 0f 01 17 33 38 42 c6 6e ┊ 64 11 da 77 5f 01 aa 32 │•••38B×n┊d•×w_•×2│43│00000120│ 3e f1 7c a1 51 f3 85 61 ┊ 03 e2 65 ca 6e 01 c9 61 │>×|×Q××a┊•×e×n•×a│You can see that as this goes on, the compression takes over more and more and the actual data becomes less and less intelligible. From this we can ascertain that the compression is done before the data is split into chunks, which makes sense because it means you can take advantage of the larger history table for the compression. This fits with the detoast_attr() function we saw earlier, which retrieved the full TOASTed value before decompressing it.
TOAST-ing strategies
Now that we’ve got a good understanding of the different TOAST techniques that Postgres utilises, is there any way we can customise Postgres’ behaviour? In fact, there is!
There are four configuration options which you can select on a per-column basis:
| Strategy | Explanation |
|---|---|
| plain | Prevents compression or out-of-lining. For non-TOAST-able types this is the only possible strategy. |
| extended | This is the default strategy that allows both compression and out-of-lining, as deemed appropriate. As we saw above, Postgres tries to compress it first and if it’s still too big, it will out-of-line it. |
| external | Allows out-of-lining but not compression. This might seem like a weird choice, but if you choose external, Postgres can actually optimise some substring operations because Postgres knows that it only needs to query specific chunk(s) of the whole TOAST slice instead of the whole thing. If your out-of-line data is compressed, you can’t do that because you need to pull in the whole TOAST slice to be able to decompress it before you can do any substring operations. |
| main | Allows compression but not out-of-lining, unless out-of-lining is absolutely necessary to be able to be able to fit the data on disk. |
So how do you change this? Let’s try it out.
1blogdb=# \d+ creative_works2 Table "public.creative_works"3 Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description4------------+---------+-----------+----------+------------------------------+----------+-------------+--------------+-------------5 id | integer | | not null | generated always as identity | plain | | |6 title | text | | | | extended | | |7 authors | jsonb | | | | extended | | |8 country_id | integer | | | | plain | | |9 content | text | | | | extended | | |10Indexes:11 "creative_works_pkey" PRIMARY KEY, btree (id)12Foreign-key constraints:13 "creative_works_country_id_fkey" FOREIGN KEY (country_id) REFERENCES countries(id)14Access method: heap15
16-- This doesn't actually change anything, it just updates the strategy for future17-- updates.18blogdb=# alter table creative_works alter column content set storage plain;19ALTER TABLE20
21-- Trigger an update for the "Ode on a Grecian Urn" poem.22blogdb=# update creative_works23blogdb-# set content = concat(content, e'\nThe end')24blogdb-# where title = 'Ode on a Grecian Urn';25UPDATE 1Let’s print out the poem data again to see what it looks like:
1$ print-cw-data 'Ode on a Grecian Urn' | head -n 302┌────────┬─────────────────────────┬─────────────────────────┬────────┬────────┐3│00000000│ 0d 00 00 00 2b 4f 64 65 ┊ 20 6f 6e 20 61 20 47 72 │_⋄⋄⋄+Ode┊ on a Gr│4│00000010│ 65 63 69 61 6e 20 55 72 ┊ 6e 01 12 5c 00 00 00 58 │ecian Ur┊n••\⋄⋄⋄X│5│00000020│ 00 00 00 5d 70 00 00 d5 ┊ 61 00 00 00 eb 00 00 00 │⋄⋄⋄]p⋄⋄×┊a⋄⋄⋄×⋄⋄⋄│6│00000030│ 6c 26 00 00 54 68 6f 75 ┊ 20 73 74 69 6c 6c 20 75 │l&⋄⋄Thou┊ still u│7│00000040│ 6e 72 61 76 69 73 68 27 ┊ 64 20 62 72 69 64 65 20 │nravish'┊d bride │8│00000050│ 6f 66 20 71 75 69 65 74 ┊ 6e 65 73 73 2c 0a 20 20 │of quiet┊ness,_ │9│00000060│ 20 20 20 20 20 54 68 6f ┊ 75 20 66 6f 73 74 65 72 │ Tho┊u foster│10│00000070│ 2d 63 68 69 6c 64 20 6f ┊ 66 20 73 69 6c 65 6e 63 │-child o┊f silenc│11│00000080│ 65 20 61 6e 64 20 73 6c ┊ 6f 77 20 74 69 6d 65 2c │e and sl┊ow time,│12│00000090│ 0a 53 79 6c 76 61 6e 20 ┊ 68 69 73 74 6f 72 69 61 │_Sylvan ┊historia│13│000000a0│ 6e 2c 20 77 68 6f 20 63 ┊ 61 6e 73 74 20 74 68 75 │n, who c┊anst thu│14│000000b0│ 73 20 65 78 70 72 65 73 ┊ 73 0a 20 20 20 20 20 20 │s expres┊s_ │15│000000c0│ 20 41 20 66 6c 6f 77 65 ┊ 72 79 20 74 61 6c 65 20 │ A flowe┊ry tale │16│000000d0│ 6d 6f 72 65 20 73 77 65 ┊ 65 74 6c 79 20 74 68 61 │more swe┊etly tha│17│000000e0│ 6e 20 6f 75 72 20 72 68 ┊ 79 6d 65 3a 0a 57 68 61 │n our rh┊yme:_Wha│18│000000f0│ 74 20 6c 65 61 66 2d 66 ┊ 72 69 6e 67 27 64 20 6c │t leaf-f┊ring'd l│19│00000100│ 65 67 65 6e 64 20 68 61 ┊ 75 6e 74 73 20 61 62 6f │egend ha┊unts abo│20│00000110│ 75 74 20 74 68 79 20 73 ┊ 68 61 70 65 0a 20 20 20 │ut thy s┊hape_ │21│00000120│ 20 20 20 20 4f 66 20 64 ┊ 65 69 74 69 65 73 20 6f │ Of d┊eities o│22│00000130│ 72 20 6d 6f 72 74 61 6c ┊ 73 2c 20 6f 72 20 6f 66 │r mortal┊s, or of│23│00000140│ 20 62 6f 74 68 2c 0a 20 ┊ 20 20 20 20 20 20 20 20 │ both,_ ┊ │24│00000150│ 20 20 20 20 20 20 49 6e ┊ 20 54 65 6d 70 65 20 6f │ In┊ Tempe o│25│00000160│ 72 20 74 68 65 20 64 61 ┊ 6c 65 73 20 6f 66 20 41 │r the da┊les of A│26│00000170│ 72 63 61 64 79 3f 0a 20 ┊ 20 20 20 20 20 20 57 68 │rcady?_ ┊ Wh│27│00000180│ 61 74 20 6d 65 6e 20 6f ┊ 72 20 67 6f 64 73 20 61 │at men o┊r gods a│28│00000190│ 72 65 20 74 68 65 73 65 ┊ 3f 20 57 68 61 74 20 6d │re these┊? What m│29│000001a0│ 61 69 64 65 6e 73 20 6c ┊ 6f 74 68 3f 0a 57 68 61 │aidens l┊oth?_Wha│30│000001b0│ 74 20 6d 61 64 20 70 75 ┊ 72 73 75 69 74 3f 20 57 │t mad pu┊rsuit? W│31│000001c0│ 68 61 74 20 73 74 72 75 ┊ 67 67 6c 65 20 74 6f 20 │hat stru┊ggle to │It’s no longer compressed! But there’s a problem – “The Waste Land” is too big to fit into the main table, but we’ve disallowed the column from being out-of-lined, so what happens if we trigger an update for this poem?
1blogdb=# vacuum full;2ERROR: row is too big: size 20280, maximum size 8160When we trigger a recomputation by doing a full vacuum, Postgres gives us an error telling us that we can’t fit the full poem in a single tuple. Let’s try “external” next:
1blogdb=# alter table creative_works alter column content set storage external;2ALTER TABLE3
4blogdb=# vacuum full;5VACUUMLet’s take a look at the data:
1$ print-cw-data 'Ode on a Grecian Urn'2┌────────┬─────────────────────────┬─────────────────────────┬────────┬────────┐3│00000000│ 0d 00 00 00 2b 4f 64 65 ┊ 20 6f 6e 20 61 20 47 72 │_⋄⋄⋄+Ode┊ on a Gr│4│00000010│ 65 63 69 61 6e 20 55 72 ┊ 6e b3 01 00 00 40 50 00 │ecian Ur┊nו⋄⋄@P⋄│5│00000020│ 00 d0 03 00 00 20 04 00 ┊ 00 80 0a 00 00 00 0a 00 │⋄ו⋄⋄ •⋄┊⋄×_⋄⋄⋄_⋄│6│00000030│ 00 00 0b 00 00 00 09 00 ┊ 00 10 08 00 00 10 6e 61 │⋄⋄•⋄⋄⋄_⋄┊⋄••⋄⋄•na│7│00000040│ 6d 65 62 69 72 74 68 5f ┊ 79 65 61 72 64 65 61 74 │mebirth_┊yeardeat│8│00000050│ 68 5f 79 65 61 72 4b 65 ┊ 61 74 73 2c 20 4a 6f 68 │h_yearKe┊ats, Joh│9│00000060│ 6e 00 20 00 00 00 00 80 ┊ 03 07 20 00 00 00 00 80 │n⋄ ⋄⋄⋄⋄×┊•• ⋄⋄⋄⋄×│10│00000070│ 1d 07 00 00 eb 00 00 00 ┊ 01 12 a3 09 00 00 9f 09 │••⋄⋄×⋄⋄⋄┊••×_⋄⋄×_│11│00000080│ 00 00 54 71 00 00 d5 61 ┊ 00 00 │⋄⋄Tq⋄⋄×a┊⋄⋄ │12└────────┴─────────────────────────┴─────────────────────────┴────────┴────────┘Our poem has now been out-of-lined! By looking at the data, we can see that the chunk ID is 54 71 00 00 = 29012:
1$ print-toast-data 29012 0 | head -n 202┌────────┬─────────────────────────┬─────────────────────────┬────────┬────────┐3│00000000│ 54 68 6f 75 20 73 74 69 ┊ 6c 6c 20 75 6e 72 61 76 │Thou sti┊ll unrav│4│00000010│ 69 73 68 27 64 20 62 72 ┊ 69 64 65 20 6f 66 20 71 │ish'd br┊ide of q│5│00000020│ 75 69 65 74 6e 65 73 73 ┊ 2c 0a 20 20 20 20 20 20 │uietness┊,_ │6│00000030│ 20 54 68 6f 75 20 66 6f ┊ 73 74 65 72 2d 63 68 69 │ Thou fo┊ster-chi│7│00000040│ 6c 64 20 6f 66 20 73 69 ┊ 6c 65 6e 63 65 20 61 6e │ld of si┊lence an│8│00000050│ 64 20 73 6c 6f 77 20 74 ┊ 69 6d 65 2c 0a 53 79 6c │d slow t┊ime,_Syl│9│00000060│ 76 61 6e 20 68 69 73 74 ┊ 6f 72 69 61 6e 2c 20 77 │van hist┊orian, w│10│00000070│ 68 6f 20 63 61 6e 73 74 ┊ 20 74 68 75 73 20 65 78 │ho canst┊ thus ex│11│00000080│ 70 72 65 73 73 0a 20 20 ┊ 20 20 20 20 20 41 20 66 │press_ ┊ A f│12│00000090│ 6c 6f 77 65 72 79 20 74 ┊ 61 6c 65 20 6d 6f 72 65 │lowery t┊ale more│13│000000a0│ 20 73 77 65 65 74 6c 79 ┊ 20 74 68 61 6e 20 6f 75 │ sweetly┊ than ou│14│000000b0│ 72 20 72 68 79 6d 65 3a ┊ 0a 57 68 61 74 20 6c 65 │r rhyme:┊_What le│15│000000c0│ 61 66 2d 66 72 69 6e 67 ┊ 27 64 20 6c 65 67 65 6e │af-fring┊'d legen│16│000000d0│ 64 20 68 61 75 6e 74 73 ┊ 20 61 62 6f 75 74 20 74 │d haunts┊ about t│17│000000e0│ 68 79 20 73 68 61 70 65 ┊ 0a 20 20 20 20 20 20 20 │hy shape┊_ │18│000000f0│ 4f 66 20 64 65 69 74 69 ┊ 65 73 20 6f 72 20 6d 6f │Of deiti┊es or mo│19│00000100│ 72 74 61 6c 73 2c 20 6f ┊ 72 20 6f 66 20 62 6f 74 │rtals, o┊r of bot│20│00000110│ 68 2c 0a 20 20 20 20 20 ┊ 20 20 20 20 20 20 20 20 │h,_ ┊ │21│00000120│ 20 20 49 6e 20 54 65 6d ┊ 70 65 20 6f 72 20 74 68 │ In Tem┊pe or th│We can see that our out-of-line data is present in its full uncompressed form, just as we’d expected. Similarly, we can try out “main”:
1blogdb=# alter table creative_works alter column content set storage main;2ALTER TABLE3
4blogdb=# vacuum full;5VACUUMNow let’s check out the data:
1$ print-cw-data 'Ode on a Grecian Urn' | head -n 202┌────────┬─────────────────────────┬─────────────────────────┬────────┬────────┐3│00000000│ 0d 00 00 00 2b 4f 64 65 ┊ 20 6f 6e 20 61 20 47 72 │_⋄⋄⋄+Ode┊ on a Gr│4│00000010│ 65 63 69 61 6e 20 55 72 ┊ 6e 01 12 5c 00 00 00 58 │ecian Ur┊n••\⋄⋄⋄X│5│00000020│ 00 00 00 a4 73 00 00 d5 ┊ 61 00 00 00 eb 00 00 00 │⋄⋄⋄×s⋄⋄×┊a⋄⋄⋄×⋄⋄⋄│6│00000030│ 1e 1b 00 00 9f 09 00 00 ┊ 00 54 68 6f 75 20 73 74 │••⋄⋄×_⋄⋄┊⋄Thou st│7│00000040│ 69 00 6c 6c 20 75 6e 72 ┊ 61 76 00 69 73 68 27 64 │i⋄ll unr┊av⋄ish'd│8│00000050│ 20 62 72 00 69 64 65 20 ┊ 6f 66 20 71 00 75 69 65 │ br⋄ide ┊of q⋄uie│9│00000060│ 74 6e 65 73 73 18 2c 0a ┊ 20 03 01 02 31 66 6f 73 │tness•,_┊ •••1fos│10│00000070│ 00 74 65 72 2d 63 68 69 ┊ 6c 02 64 01 27 73 69 6c │⋄ter-chi┊l•d•'sil│11│00000080│ 65 6e 63 00 65 20 61 6e ┊ 64 20 73 6c 00 6f 77 20 │enc⋄e an┊d sl⋄ow │12│00000090│ 74 69 6d 65 2c 00 0a 53 ┊ 79 6c 76 61 6e 20 00 68 │time,⋄_S┊ylvan ⋄h│13│000000a0│ 69 73 74 6f 72 69 61 00 ┊ 6e 2c 20 77 68 6f 20 63 │istoria⋄┊n, who c│14│000000b0│ 00 61 6e 73 74 20 74 68 ┊ 75 00 73 20 65 78 70 72 │⋄anst th┊u⋄s expr│15│000000c0│ 65 73 02 73 05 5c 41 20 ┊ 66 6c 6f 77 00 65 72 79 │es•s•\A ┊flow⋄ery│16│000000d0│ 20 74 61 6c 65 00 20 6d ┊ 6f 72 65 20 73 77 00 65 │ tale⋄ m┊ore sw⋄e│17│000000e0│ 65 74 6c 79 20 74 68 00 ┊ 61 6e 20 6f 75 72 20 72 │etly th⋄┊an our r│18│000000f0│ 00 68 79 6d 65 3a 0a 57 ┊ 68 00 61 74 20 6c 65 61 │⋄hyme:_W┊h⋄at lea│19│00000100│ 66 2d 00 66 72 69 6e 67 ┊ 27 64 20 00 6c 65 67 65 │f-⋄fring┊'d ⋄lege│20│00000110│ 6e 64 20 68 00 61 75 6e ┊ 74 73 20 61 62 04 6f 75 │nd h⋄aun┊ts ab•ou│21│00000120│ 01 66 79 20 73 68 61 04 ┊ 70 65 05 63 4f 66 20 64 │•fy sha•┊pe•cOf d│We’re back to our compressed form. What’s more, interestingly, changing the storage type for the content column has also changed how the authors jsonb blob is being stored. Instead of being stored inline, as it was before, it’s now been moved to external. You can spot this by seeing the characteristic 01 12 after the end of the title of the poem, which indicates that the next field is stored “external on-disk”.
What’s happening here is that Postgres is doing it’s utmost effort to make as much space as possible in the main table to ensure the content column has the maximum likelihood of being able to be stored inline. It’s still not enough for The Waste Land which is never going to fit in the main table, but it doesn’t produce an error this time because “main” still allows out-of-lining as a last resort.
When should you use each strategy?
Depending on your specific use-case, different strategies can produce different performance characteristics.
For instance, if you are doing lots of substring operations on really wide string values, using “external” is probably a good bet as long as you don’t mind the increased size on-disk.
If you’re always pulling the whole row including the full variable length attribute in question, you might find that using main reduces the time spent pulling data out of external toast tables.
On the other hand, if you are often pulling through all the values other than the variable-length attribute in question, it might make more sense to out-of-line it so that you don’t have to skip over these large values in the main table when doing a read of contiguous rows on disk. Having smaller rows can often lead to performance improvements due purely to the smaller row size, meaning more rows fit in the shared buffer cache and that sorts can more often be done entirely in-memory.
As always, it’s never a good idea to base production decisions around abstract thinking when it comes to database performance – there can be a million possible things that can affect database performance based on your individual use case and it only takes one limiting factor to ruin your query performance. Always do proper performance comparisons with real or representative data and base your decisions on a thorough analysis of all those statistics and explain analyse outputs8.
Conclusion
If you’ve made it this far, you should have a thorough understanding of how Postgres handles variable length attributes including compression and out-of-lining. We talked about how Postgres indicates which type of struct is being used to store the variable length attribute header information and how to track down TOAST slices based on the data within the main table.
We talked about the different TOAST strategies you can select within your schema and how this can affect the performance characteristics of your database.
Hopefully, this’ll come in useful for you one day when you’re analysing and optimising some particularly nasty performance issues. If nothing else, it’s an impressive thing to be able to talk about in detail if you’re in a job interview.
I’ll leave you with my favourite excerpt from these poems:
And I will show you something different from either
Your shadow at morning striding behind you
Or your shadow at evening rising to meet you;
I will show you fear in a handful of dust.
— T. S. Eliot, The Waste Land
Further reading
- PostgreSQL documentation – 73.2. TOAST
- PostgreSQL source code documentation
- PostgreSQL wiki – TOAST
- Quadcode on Medium – TOAST tables in PostgreSQL
- Crunchy Data blog – Postgres TOAST: The Greatest Thing Since Sliced Bread?
- Timescale blog – What Is TOAST (and Why It Isn’t Enough for Data Compression in Postgres)
Footnotes
-
T. S. Eliot was born an American but later renounced his American citizenship to become a naturalised British citizen. The Waste Land was written in 1922 after his move to England but before his transition from American to British citizen, so I’ve put “US” down for country – don’t @ me. ↩
-
Fun fact: Ozymandias was written as a playful challenge between Shelley and his friend Horace Smith, who tasked each other with having a sonnet published in The Examiner under pen names with the title of and under the topic of Ozymandias, the Greek name for the pharaoh Ramesses II. They both managed to get their sonnets published but Shelley’s version is now one of the most popular and impactful poems in the English language, so think we can say that Shelley won the competition. ↩
-
In fact this value doesn’t have the usual 4-byte varlena header, it’s got a 2-byte header instead – we’ll see this in action in just a minute. ↩
-
The smaller and bigger were easier but finding a poem of just the right length to be compressed but not out-of-lined was tricky – big shout out to that Grecian urn 🙏🏻⚱️ ↩
-
I checked – there is indeed an em dash in there, on the penultimate line, in fact: “Beauty is truth, truth beauty,—that is all/Ye know on earth, and all ye need to know.” This is untrue – you also need to know about how Postgres handles variable length attributes, obviously. ↩
-
Remember that I’m running this on a little endian machine (and you most likely are too) so we need to swap the bytes around, so
ff 66 00 00becomes0x000066ffwhen we want to convert it to decimal. ↩ -
You can actually convert from hex to decimal within the Postgres query itself by replacing
where chunk_id = 26367withwhere chunk_id = x'66ff'::int. Neat! ↩ -
If you’re wondering, yes I do insist on using the British spelling for
explain analyse. Why would Postgres implement the alias unless they want snobby Brits like me to use it? ↩
Comments